Úvod
 Umělá inteligence je o používání strojů ke zlepšení života a životního stylu lidí tím, že jejich všední životy budou zajímavé a nadbytečné úkoly jednoduché. Umělá inteligence by nikdy neměla být dominantní silou, ale doplňkovou silou, která spolupracuje s lidmi, aby vyřešila nepravděpodobné a připravila cestu pro kolektivní evoluci.
Umělá inteligence je o používání strojů ke zlepšení života a životního stylu lidí tím, že jejich všední životy budou zajímavé a nadbytečné úkoly jednoduché. Umělá inteligence by nikdy neměla být dominantní silou, ale doplňkovou silou, která spolupracuje s lidmi, aby vyřešila nepravděpodobné a připravila cestu pro kolektivní evoluci.
Od nynějška kráčíme správnou cestou a s pomocí AI dochází k významným průlomům napříč odvětvími. Pokud vezmete například zdravotní péči, systémy umělé inteligence doprovázené modely strojového učení pomáhají odborníkům lépe porozumět rakovině a navrhnout její léčbu. Neurologické poruchy a obavy, jako je PTSD, se léčí pomocí AI. Vakcíny jsou vyvíjeny rychlým tempem díky klinickým zkouškám a simulacím využívajícím umělou inteligenci.
Nejen zdravotnictví, každé jednotlivé odvětví nebo segment, kterého se AI dotýká, prochází revolucí. Autonomní vozidla, chytré obchody, nositelná zařízení jako FitBit a dokonce i naše fotoaparáty chytrých telefonů jsou schopny zachytit lepší snímky našich tváří pomocí AI.
Díky inovacím, které se dějí v prostoru AI, se společnosti vrhají do spektra s různými případy použití a řešeními. Díky tomu se očekává, že globální trh s umělou inteligencí dosáhne do konce roku 267 tržní hodnoty kolem 2027 miliard USD. Kromě toho přibližně 37 % podniků již implementuje řešení umělé inteligence do svých procesů a produktů.
Ještě zajímavější je, že téměř 77 % produktů a služeb, které dnes používáme, je poháněno umělou inteligencí. Jak se podnikům daří dělat nemožné s umělou inteligencí, protože technologická koncepce výrazně narůstá napříč vertikálami?

 Jak mohou zařízení tak jednoduchá, jako jsou hodinky, přesně předpovídat infarkty u lidí? Jak je možné, že auta a automobily, které vždy vyžadovaly řidiče, najednou jezdí po silnicích méně?
Jak mohou zařízení tak jednoduchá, jako jsou hodinky, přesně předpovídat infarkty u lidí? Jak je možné, že auta a automobily, které vždy vyžadovaly řidiče, najednou jezdí po silnicích méně?
Jak nás chatboti přimějí věřit, že mluvíme s jiným člověkem na druhé straně?
Pokud pozorujete odpověď na každou otázku, scvrkává se pouze na jeden prvek – DATA. Data jsou středobodem všech operací a procesů specifických pro umělou inteligenci. Jsou to data, která strojům pomáhají porozumět konceptům, zpracovávat vstupy a poskytovat přesné výsledky.
Všechna hlavní řešení AI, která existují, jsou produkty klíčového procesu, kterému říkáme sběr dat nebo získávání dat nebo trénovací data AI.
Tato obsáhlá příručka vám pomůže pochopit, co to je a proč je to důležité.
Co je sběr dat AI?
Stroje nemají vlastní mysl. Absence tohoto abstraktního konceptu je činí bez názorů, faktů a schopností, jako je uvažování, poznávání a další. Jsou to jen nepohyblivé krabice nebo zařízení zabírající prostor. Chcete-li je přeměnit na výkonná média, potřebujete algoritmy a především data.
 Algoritmy, které jsou vyvíjeny, potřebují něco, na čem by se dalo pracovat a zpracovávat, a tím něčím jsou data, která jsou relevantní, kontextová a aktuální. Proces shromažďování takových dat pro stroje, aby sloužily jejich zamýšleným účelům, se nazývá sběr dat AI.
Algoritmy, které jsou vyvíjeny, potřebují něco, na čem by se dalo pracovat a zpracovávat, a tím něčím jsou data, která jsou relevantní, kontextová a aktuální. Proces shromažďování takových dat pro stroje, aby sloužily jejich zamýšleným účelům, se nazývá sběr dat AI.
Každý jednotlivý produkt nebo řešení s umělou inteligencí, které dnes používáme, a výsledky, které nabízejí, pocházejí z let školení, vývoje a optimalizace. Od zařízení, která nabízejí navigační trasy až po složité systémy, které předpovídají selhání zařízení několik dní předem, každá jednotlivá entita prošla roky školení AI, aby byla schopna poskytovat přesné výsledky.
Sběr dat AI je předběžným krokem v procesu vývoje umělé inteligence, který hned od začátku určuje, jak efektivní a efektivní bude systém umělé inteligence. Právě proces získávání relevantních datových sad z nesčetných zdrojů pomůže modelům umělé inteligence zpracovat detaily lépe a chrlit smysluplné výsledky.




Jak sbírat data pro strojové učení?
 Tady to začíná být trochu složitější. Od začátku se zdá, že máte na mysli řešení skutečného problému, víte, že AI by byla ideální cesta, jak toho dosáhnout, a vyvinuli jste své modely. Nyní se ale nacházíte v klíčové fázi, kdy musíte zahájit tréninkové procesy AI. K tomu, aby se vaše modely naučily koncepty a přinášely výsledky, potřebujete dostatek tréninkových dat AI. Potřebujete také ověřovací data, abyste mohli otestovat své výsledky a optimalizovat své algoritmy.
Tady to začíná být trochu složitější. Od začátku se zdá, že máte na mysli řešení skutečného problému, víte, že AI by byla ideální cesta, jak toho dosáhnout, a vyvinuli jste své modely. Nyní se ale nacházíte v klíčové fázi, kdy musíte zahájit tréninkové procesy AI. K tomu, aby se vaše modely naučily koncepty a přinášely výsledky, potřebujete dostatek tréninkových dat AI. Potřebujete také ověřovací data, abyste mohli otestovat své výsledky a optimalizovat své algoritmy.
Jak tedy získáváte svá data? Jaká data potřebujete a kolik z nich? Jaké jsou různé zdroje pro získání relevantních dat?
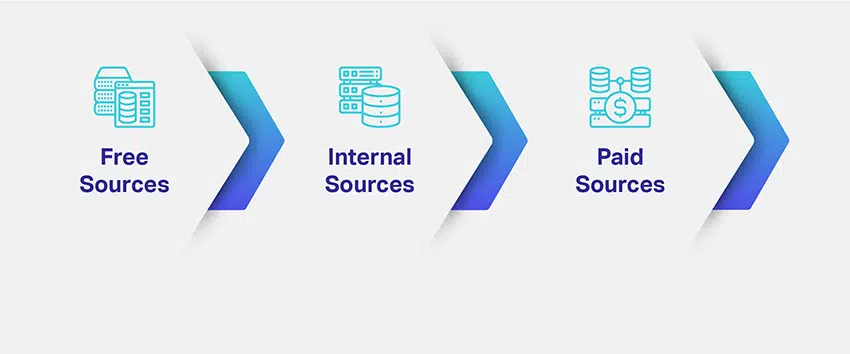
Společnosti posoudí výklenek a účel svých modelů ML a načrtnou potenciální způsoby, jak získat relevantní datové sady. Definování potřebného datového typu řeší hlavní část vašich starostí o získávání dat. Pro lepší představu existují různé kanály, cesty, zdroje nebo média pro sběr dat:
Jak špatná data ovlivňují vaše ambice v oblasti umělé inteligence?
Vyjmenovali jsme tři nejběžnější zdroje dat z toho důvodu, abyste měli představu, jak přistupovat ke sběru dat a získávání zdrojů. V tuto chvíli je však nezbytné také pochopit, že vaše rozhodnutí může vždy rozhodnout o osudu vašeho řešení AI.
Podobně jako mohou vysoce kvalitní tréninková data AI pomoci vašemu modelu poskytovat přesné a včasné výsledky, mohou špatná tréninková data také narušit vaše modely AI, zkreslit výsledky, zavést zkreslení a nabídnout další nežádoucí důsledky.
Ale proč se to děje? Neměla by nějaká data trénovat a optimalizovat váš model AI? Upřímně, ne. Pojďme tomu rozumět dále.
Špatná data – co to je?
 Špatná data jsou jakákoli data, která jsou irelevantní, nesprávná, neúplná nebo neobjektivní. Díky špatně definovaným strategiím sběru dat většina datových vědců a odborníci na anotace jsou nuceni pracovat na špatných datech.
Špatná data jsou jakákoli data, která jsou irelevantní, nesprávná, neúplná nebo neobjektivní. Díky špatně definovaným strategiím sběru dat většina datových vědců a odborníci na anotace jsou nuceni pracovat na špatných datech.
Rozdíl mezi nestrukturovanými a špatnými daty je ten, že přehledy o nestrukturovaných datech jsou všude. Ale v podstatě by mohly být užitečné bez ohledu na to. Pokud by datoví vědci věnovali více času, byli by stále schopni extrahovat relevantní informace z nestrukturovaných datových sad. To však není případ špatných dat. Tyto datové sady neobsahují žádné/omezené poznatky nebo informace, které jsou cenné nebo relevantní pro váš projekt AI nebo jeho školicí účely.
Když tedy získáváte své datové sady z volných zdrojů nebo máte volně vytvořené interní datové kontaktní body, je vysoce pravděpodobné, že si stáhnete nebo vygenerujete špatná data. Když vaši vědci pracují na špatných datech, nejen že plýtváte lidskými hodinami, ale také tlačíte na uvedení vašeho produktu na trh.
Pokud stále nemáte jasno v tom, co mohou špatná data udělat s vašimi ambicemi, zde je stručný seznam:
- Strávíte nespočet hodin získáváním špatných dat a plýtváte hodinami, úsilím a penězi na zdroje.
- Špatná data vám mohou způsobit právní problémy, pokud si toho nevšimnete, a mohou snížit efektivitu vaší AI
modely. - Když spustíte svůj produkt vyškolený na špatných datech, ovlivní to uživatelský dojem
- Špatná data by mohla způsobit, že výsledky a závěry budou zkreslené, což by mohlo přinést další negativní reakce.
Pokud se tedy ptáte, zda na to existuje řešení, ve skutečnosti existuje.
Poskytovatelé AI Training Data na záchranu
 Jedním ze základních řešení je jít za dodavatelem dat (placené zdroje). Poskytovatelé školicích dat AI zajišťují, že to, co obdržíte, je přesné a relevantní, a že vám budou soubory dat doručeny ve strukturované podobě. Nemusíte být zapojeni do potíží s přesunem z portálu na portál při hledání datových sad.
Jedním ze základních řešení je jít za dodavatelem dat (placené zdroje). Poskytovatelé školicích dat AI zajišťují, že to, co obdržíte, je přesné a relevantní, a že vám budou soubory dat doručeny ve strukturované podobě. Nemusíte být zapojeni do potíží s přesunem z portálu na portál při hledání datových sad.
Jediné, co musíte udělat, je vzít data a vycvičit své modely AI k dokonalosti. Díky tomu jsme si jisti, že vaše další otázka se týká výdajů spojených se spoluprací s dodavateli dat. Chápeme, že někteří z vás již pracují na mentálním rozpočtu a přesně tam míříme také příště.
Faktory, které je třeba vzít v úvahu při vymýšlení efektivního rozpočtu pro váš projekt sběru dat
Školení AI je systematický přístup, a proto se rozpočtování stává jeho nedílnou součástí. Faktory, jako je návratnost investic, přesnost výsledků, školicí metodiky a další, by měly být zváženy předtím, než investujete obrovské množství peněz do vývoje AI. Mnoho projektových manažerů nebo majitelů firem v této fázi tápe. Dělají unáhlená rozhodnutí, která přinášejí nevratné změny v procesu vývoje jejich produktů, což je nakonec nutí utrácet více.
Tato část vám však poskytne ty správné poznatky. Když sedíte a pracujete na rozpočtu na školení AI, jsou nevyhnutelné tři věci nebo faktory.

Podívejme se na každou podrobně.
Objem dat, který potřebujete
Celou dobu jsme říkali, že účinnost a přesnost vašeho modelu AI závisí na tom, jak moc je trénovaný. To znamená, že čím větší objem datových sad, tím více učení. Ale to je velmi vágní. Abychom tuto představu vyčíslili, Dimensional Research zveřejnil zprávu, která odhalila, že podniky potřebují minimálně 100,000 XNUMX vzorových datových sad pro trénování svých modelů AI.
Pod pojmem 100,000 100,000 datových sad rozumíme XNUMX XNUMX kvalitních a relevantních datových sad. Tyto datové sady by měly mít všechny základní atributy, anotace a poznatky potřebné pro vaše algoritmy a modely strojového učení ke zpracování informací a provádění zamýšlených úkolů.
S tímto obecným pravidlem dále pochopíme, že objem dat, který potřebujete, závisí také na dalším složitém faktoru, kterým je případ použití vaší firmy. O tom, kolik dat potřebujete, také rozhoduje to, co se svým produktem nebo řešením zamýšlíte udělat. Například firma vytvářející modul doporučení by měla jiné požadavky na objem dat než společnost, která buduje chatbota.
Cenová strategie dat
Až dokončíte finalizaci toho, kolik dat skutečně potřebujete, musíte dále pracovat na strategii stanovení cen za data. Jednoduše to znamená, jak byste platili za datové sady, které si pořídíte nebo vytvoříte.
Obecně se jedná o běžné cenové strategie používané na trhu:
| Datový typ | Cenová strategie |
|---|---|
| Cena za jeden obrazový soubor | |
| Cena za sekundu, minutu, hodinu nebo individuální snímek | |
| Cena za sekundu, minutu nebo hodinu | |
| Cena za slovo nebo větu |
Ale počkej. To je opět pravidlo. Skutečné náklady na pořízení datových sad také závisí na faktorech, jako jsou:
- Jedinečný segment trhu, demografie nebo geografie, odkud je třeba získávat datové sady
- Složitost vašeho případu použití
- Kolik dat potřebujete?
- Váš čas na trh
- Jakékoli požadavky na míru a další
Pokud budete pozorovat, budete vědět, že náklady na získání velkého množství obrázků pro váš projekt AI mohou být nižší, ale pokud máte příliš mnoho specifikací, ceny mohou vystřelit nahoru.
Vaše strategie získávání zdrojů
To je ošemetné. Jak jste viděli, existují různé způsoby, jak generovat nebo získávat data pro vaše modely AI. Zdravý rozum by diktoval, že bezplatné zdroje jsou nejlepší, protože si můžete stáhnout požadované objemy datových sad zdarma bez jakýchkoli komplikací.
Právě teď by se také zdálo, že placené zdroje jsou příliš drahé. Ale to je místo, kde se přidává vrstva komplikací. Když získáváte datové sady z volných zdrojů, strávíte další množství času a úsilí čištěním datových sad, jejich kompilací do formátu specifického pro vaši firmu a následným individuálním přidáváním poznámek. V tomto procesu vám vznikají provozní náklady.
U placených zdrojů je platba jednorázová a navíc získáte strojově připravené datové sady v čase, který požadujete. Cenová výhodnost je zde velmi subjektivní. Pokud máte pocit, že byste si mohli dovolit trávit čas anotováním bezplatných datových sad, můžete odpovídajícím způsobem rozpočet. A pokud se domníváte, že vaše konkurence je nelítostná a s omezeným časem uvedení na trh, můžete na trhu vytvořit vlnový efekt, měli byste preferovat placené zdroje.
Rozpočtování je o rozčlenění specifik a jasném definování každého fragmentu. Tyto tři faktory by vám měly sloužit jako plán pro váš budoucí rozpočtový proces školení AI.
Šetříte na výdajích díky vlastnímu sběru dat?
 Při sestavování rozpočtu jsme prozkoumali, jak vás volné zdroje nutí dlouhodobě utrácet více. V tu chvíli byste se automaticky zajímali o nákladovou efektivitu interního procesu získávání dat.
Při sestavování rozpočtu jsme prozkoumali, jak vás volné zdroje nutí dlouhodobě utrácet více. V tu chvíli byste se automaticky zajímali o nákladovou efektivitu interního procesu získávání dat.
Víme, že stále váháte s placenými zdroji, a proto tato sekce vyčistí vaši skepsi vůči nim a osvětlí skryté náklady spojené s generováním vlastních dat.
Je pořízení interních dat drahé?
Ano to je!
Nyní je zde podrobná odpověď. Výdaj je cokoliv, co utratíte. Při diskuzi o bezplatných zdrojích jsme odhalili, že v procesu utrácíte peníze, čas a úsilí. To platí i pro vnitropodnikový sběr dat.
 Vzhledem k tomu, že máte vlastní kontaktní body nebo datové cesty, neznamená to, že byste je měli strojově připravené datové sady na konci. Data, která vygenerujete, budou stále většinou nezpracovaná a nestrukturovaná. Můžete mít všechna potřebná data na jednom místě, ale to, co data obsahují, bude všude.
Vzhledem k tomu, že máte vlastní kontaktní body nebo datové cesty, neznamená to, že byste je měli strojově připravené datové sady na konci. Data, která vygenerujete, budou stále většinou nezpracovaná a nestrukturovaná. Můžete mít všechna potřebná data na jednom místě, ale to, co data obsahují, bude všude.
Nakonec byste skončili utrácením za platby svým zaměstnancům, datovým vědcům, anotátorům, profesionálům v oblasti zajišťování kvality a dalším. Budete také utrácet za předplatné nástrojů pro anotaci a
náklady na údržbu CMS, CRM a další infrastruktury.
Kromě toho musí mít datové sady problémy se zkreslením a přesností, které je třeba ručně roztřídit. A pokud máte problém s opotřebováním ve svém tréninkovém datovém týmu AI, budete muset utrácet za nábor nových členů, orientovat je ve vašich procesech, trénovat je k používání vašich nástrojů a další.
Skončíte tak, že utratíte více, než kolik byste nakonec vydělali v dlouhodobém horizontu. Existují také výdaje na anotaci. V každém daném okamžiku jsou celkové náklady vynaložené na práci s interními daty:
Vzniklé náklady = počet anotátorů * Cena za anotátora + náklady na platformu
Pokud je váš kalendář školení AI naplánován na měsíce, představte si výdaje, které byste neustále vynakládali. Je to tedy ideální řešení pro získávání dat nebo existuje nějaká alternativa?
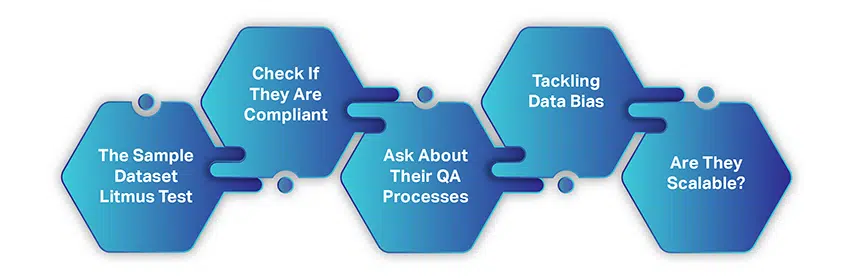
Jak vybrat správnou společnost pro sběr dat AI
Výběr společnosti pro sběr dat AI není tak komplikovaný ani časově náročný jako sběr dat z volných zdrojů. Existuje jen několik jednoduchých faktorů, které musíte zvážit a poté si potřást rukou pro spolupráci.
Když začínáte hledat dodavatele dat, předpokládáme, že jste postupovali a zvažovali vše, o čem jsme dosud diskutovali. Zde je však rychlá rekapitulace:
- Máte na mysli dobře definovaný případ použití
- Váš segment trhu a požadavky na data jsou jasně stanoveny
- Váš rozpočet je na místě
- A máte představu o objemu dat, který potřebujete
Po zaškrtnutí těchto položek pochopíme, jak můžete hledat ideálního poskytovatele datových služeb pro trénink.