
Umělá inteligence a velká data mají potenciál najít řešení globálních problémů a zároveň upřednostňovat lokální problémy a transformovat svět mnoha hlubokými způsoby. Umělá inteligence přináší řešení pro všechny – a ve všech prostředích, od domácností po pracoviště. Počítače AI s Strojové učení školení, dokáže simulovat inteligentní chování a konverzace automatizovaným, ale personalizovaným způsobem.
Přesto AI čelí problému inkluze a je často zaujatá. Naštěstí zaměření na etika umělé inteligence může přinést nové možnosti, pokud jde o diverzifikaci a začlenění, odstraněním nevědomého zkreslení prostřednictvím různých tréninkových dat.
Význam rozmanitosti v trénovacích datech AI
 Rozmanitost a kvalita trénovacích dat spolu souvisí, protože jedno ovlivňuje druhé a ovlivňuje výsledek řešení AI. Úspěch řešení AI závisí na různorodá data je to natrénováno. Rozmanitost dat zabraňuje přeplnění AI – to znamená, že model funguje nebo se učí pouze z dat používaných k trénování. Při nadměrném vybavení nemůže model umělé inteligence poskytnout výsledky při testování na datech, která se nepoužívají při tréninku.
Rozmanitost a kvalita trénovacích dat spolu souvisí, protože jedno ovlivňuje druhé a ovlivňuje výsledek řešení AI. Úspěch řešení AI závisí na různorodá data je to natrénováno. Rozmanitost dat zabraňuje přeplnění AI – to znamená, že model funguje nebo se učí pouze z dat používaných k trénování. Při nadměrném vybavení nemůže model umělé inteligence poskytnout výsledky při testování na datech, která se nepoužívají při tréninku.
Aktuální stav výcviku AI datum
Nerovnost nebo nedostatek rozmanitosti v datech by vedly k nespravedlivým, neetickým a nezahrnutým řešením umělé inteligence, která by mohla prohloubit diskriminaci. Ale jak a proč souvisí rozmanitost dat s řešeními AI?
Nerovnoměrné zastoupení všech tříd vede k chybné identifikaci tváří – jedním z důležitých příkladů jsou Fotky Google, které klasifikovaly černý pár jako „gorily“. A Meta vyzve uživatele, který sleduje video černochů, zda by si uživatel přál „pokračovat ve sledování videí primátů“.
Například nepřesná nebo nesprávná klasifikace etnických nebo rasových menšin, zejména u chatbotů, by mohla vést k předsudkům v systémech školení AI. Podle zprávy za rok 2019 Diskriminační systémy – pohlaví, rasa, síla v AI, více než 80 % učitelů AI jsou muži; ženy zabývající se umělou inteligencí na FB tvoří pouze 15 % a 10 % na Googlu.
Vliv různorodých školicích dat na výkon AI
 Vynechání konkrétních skupin a komunit z reprezentace dat může vést ke zkresleným algoritmům.
Vynechání konkrétních skupin a komunit z reprezentace dat může vést ke zkresleným algoritmům.
Zkreslení dat je často náhodně zavedeno do datových systémů – podvzorkováním určitých ras nebo skupin. Když jsou systémy rozpoznávání obličeje trénovány na různých obličejích, pomáhá to modelu identifikovat specifické rysy, jako je poloha obličejových orgánů a barevné variace.
Dalším výsledkem nevyvážené frekvence štítků je, že systém může menšinu považovat za anomálii, když je pod tlakem, aby během krátké doby vyprodukoval výstup.
Dosažení rozmanitosti v datech školení AI
Na druhou stranu je generování různorodé datové sady také výzvou. Naprostý nedostatek údajů o určitých třídách by mohl vést k nedostatečnému zastoupení. Lze to zmírnit tím, že týmy vývojářů AI budou rozmanitější, pokud jde o dovednosti, etnický původ, rasu, pohlaví, disciplínu a další. Navíc, Ideální způsob, jak řešit problémy s rozmanitostí dat v AI, je čelit jim od začátku, místo toho, abyste se snažili napravit to, co se stalo – vkládání rozmanitosti do fáze shromažďování a ošetřování dat.
Bez ohledu na humbuk kolem AI to stále závisí na datech shromážděných, vybraných a vyškolených lidmi. Vrozená zaujatost u lidí se projeví v jimi shromážděných datech a tato nevědomá zaujatost se vkrádá i do modelů ML.
Kroky pro shromažďování a správu různých tréninkových dat
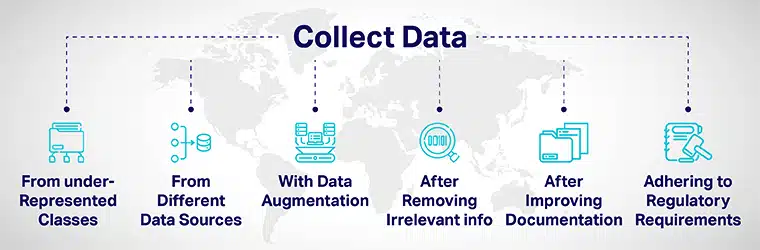
Diverzita dat lze dosáhnout:
- Promyšleně přidejte další data z nedostatečně zastoupených tříd a vystavte své modely různým datovým bodům.
- Shromažďováním dat z různých zdrojů dat.
- Rozšiřováním dat nebo umělou manipulací s datovými sadami za účelem zvýšení/zahrnutí nových datových bodů výrazně odlišných od původních datových bodů.
- Při najímání uchazečů do procesu vývoje AI odstraňte z aplikace všechny informace, které nejsou relevantní pro práci.
- Zlepšení transparentnosti a odpovědnosti zlepšením dokumentace vývoje a hodnocení modelů.
- Zavádění předpisů pro budování rozmanitosti a začlenění do AI systémy od základní úrovně. Různé vlády vypracovaly pokyny k zajištění rozmanitosti a zmírnění zkreslení umělé inteligence, které může přinést nespravedlivé výsledky.
[Přečtěte si také: Zjistěte více o procesu shromažďování dat pro školení AI ]
Proč investovat do čističky vzduchu?
V současné době se pouze několik velkých technologických společností a výukových center zabývá výhradně vývojem řešení AI. Tyto elitní prostory jsou ponořené do vyloučení, diskriminace a zaujatosti. Nicméně toto jsou prostory, kde se AI vyvíjí, a logika těchto pokročilých systémů AI je plná stejných předsudků, diskriminace a vyloučení, které nesou nedostatečně zastoupené skupiny.
Při diskusi o diverzitě a nediskriminaci je důležité klást otázky lidem, kterým prospívá, a těm, kterým škodí. Měli bychom se také podívat na to, koho znevýhodňuje – vynucením představy „normálního“ člověka by AI mohla potenciálně ohrozit „ostatní“.
Diskuse o rozmanitosti dat AI bez uznání mocenských vztahů, spravedlnosti a spravedlnosti neukáže větší obrázek. Abychom plně porozuměli rozsahu rozmanitosti tréninkových dat AI a tomu, jak mohou lidé a AI společně zmírnit tuto krizi, oslovte inženýry v Shaip. Máme různé inženýry AI, kteří mohou poskytnout dynamická a různorodá data pro vaše řešení AI.


