


Co je konverzační AI
Konverzační umělá inteligence je pokročilá forma umělé inteligence, která umožňuje strojům zapojit se do interaktivních dialogů podobných lidem s uživateli. Tato technologie rozumí a interpretuje lidskou řeč, aby simulovala přirozené konverzace. Může se učit z interakcí v průběhu času reagovat kontextově.
Konverzační systémy AI jsou široce používány v aplikacích, jako jsou chatboti, hlasoví asistenti a platformy zákaznické podpory napříč digitálními a telekomunikačními kanály.
Konverzační trh AI zažívá v posledních letech rychlý růst. Konverzační umělá inteligence, původně vyvinutá pro zábavní účely, se stala nedílnou součástí digitálního ekosystému. Zde jsou některé klíčové statistiky, které ilustrují jeho dopad:
- Globální trh s konverzační umělou inteligencí byl v roce 6.8 oceněn na 2021 miliardy USD a předpokládá se, že do roku 18.4 vzroste na 2026 miliardy USD při CAGR 22.6 %. Očekává se, že do roku 2028 dosáhne velikost trhu $ 29.8 miliardy.
- Navzdory své rozšířenosti, 63% uživatelů si neuvědomuje, že ve svém každodenním životě používají umělou inteligenci.
- A Průzkum Gartner zjistili, že mnoho firem označilo chatboty za svou primární aplikaci AI, přičemž se očekává, že téměř 70 % bílých límečků bude do roku 2022 denně komunikovat s konverzačními platformami.
- Od pandemie se objem interakcí zpracovávaných konverzačními agenty zvýšil až o tolik 250% napříč více průmyslovými odvětvími.
- Podíl marketérů využívajících umělou inteligenci pro digitální marketing po celém světě dramaticky vzrostl, z 29 % v roce 2018 na 84% v 2020.
- V 2022, 91% dospělých uživatelů hlasových asistentů používalo na svých chytrých telefonech technologii konverzační umělé inteligence.
- Prohlížení a vyhledávání produktů byly top nákupní aktivity provedené pomocí technologie hlasového asistenta mezi uživateli v USA v průzkumu z roku 2021.
- Mezi technologickými profesionály po celém světě, téměř 80% používat virtuální asistenty pro zákaznický servis.
- Do roku 2024 se 73 % severoamerických osob s rozhodovací pravomocí v oblasti zákaznických služeb domnívá, že online chat, videochat, chatboti nebo sociální média budou nejpoužívanější kanály zákaznických služeb.
- V průzkumu z roku 2021 86% Američtí manažeři souhlasili s tím, že AI se v jejich společnosti stane „mainstreamovou technologií“.
- Od února 2022 53% dospělých z USA v posledním roce komunikovalo s chatbotem AI pro zákaznický servis.
- V 2022, 3.5 miliardy aplikace chatbotů byly přístupné po celém světě.
- Projekt tři hlavní důvody Američtí spotřebitelé používají chatbota pro pracovní dobu (18 %), informace o produktech (17 %) a požadavky na služby zákazníkům (16 %).
Tyto statistiky zdůrazňují rostoucí přijetí a vliv konverzační umělé inteligence v různých odvětvích a spotřebitelském chování.
Jak funguje konverzační umělá inteligence
Konverzační umělá inteligence využívá zpracování přirozeného jazyka (NLP) a další sofistikované algoritmy k zapojení do dialogů bohatých na kontext. Jak se AI setkává s širším rozsahem uživatelských vstupů, zlepšuje své rozpoznávání vzorů a prediktivní schopnosti. Proces konverzační AI zapojení uživatelů lze rozdělit do čtyř klíčových kroků:

Krok 1: Vstupní kolekce – Uživatelé poskytují svůj vstup buď prostřednictvím textu nebo hlasu.
Krok 2: Vstupní zpracování – Pokud je vstup v textové podobě, k extrakci významu slov se používá porozumění přirozenému jazyku (NLU). U hlasových vstupů se nejprve používá automatické rozpoznávání řeči (ASR), které převádí zvuk na jazykové tokeny, které lze dále analyzovat.
Krok 3: Generování odezvy – Techniky generování přirozeného jazyka jsou využívány k odpovídající reakci na dotaz uživatele.
Krok 4: Neustálé zlepšování – Systémy konverzační umělé inteligence analyzují vstupy uživatelů v průběhu času a zpřesňují jejich reakce, aby byla zajištěna přesnost a relevance.

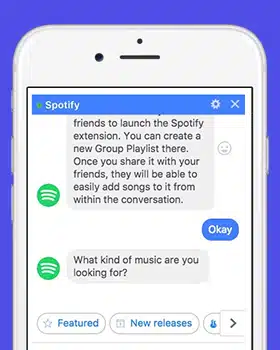
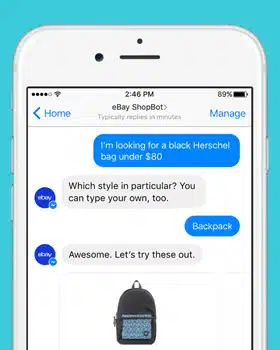

Zmírněte běžné problémy s daty v konverzační umělé inteligenci
Konverzační umělá inteligence dynamicky mění komunikaci mezi člověkem a počítačem. A mnoho podniků má zájem o vývoj pokročilých konverzačních nástrojů a aplikací AI, které mohou změnit způsob podnikání. Než však vyvinete chatbota, který může usnadnit lepší komunikaci mezi vámi a vašimi zákazníky, musíte se podívat na mnoho vývojových úskalí, kterým můžete čelit.
Jazyková rozmanitost
 Vyvinout chatovacího asistenta, který umí pracovat v několika jazycích, je náročné. Kromě toho naprostá rozmanitost globálních jazyků dělá problém vyvinout chatbota, který bez problémů poskytuje zákaznický servis všem zákazníkům.
Vyvinout chatovacího asistenta, který umí pracovat v několika jazycích, je náročné. Kromě toho naprostá rozmanitost globálních jazyků dělá problém vyvinout chatbota, který bez problémů poskytuje zákaznický servis všem zákazníkům.
V 2022, asi 1.5 miliard lidé po celém světě mluvili anglicky, následovala mandarínská čínština s 1.1 miliardou mluvčích. Přestože angličtina je celosvětově nejrozšířenějším a nejstudovanějším cizím jazykem, jen asi 20% mluví tím světová populace. Díky tomu zbytek světové populace – 80 % – mluví jinými jazyky než anglicky. Takže při vývoji chatbota musíte vzít v úvahu také jazykovou rozmanitost.
Jazyková variabilita
Lidské bytosti mluví různými jazyky a stejnou řečí odlišně. Pro stroj je bohužel stále nemožné plně porozumět variabilitě mluvené řeči, zohledňující emoce, dialekty, výslovnost, přízvuky a nuance.
Naše slova a výběr jazyka se také odráží v tom, jak píšeme. Lze očekávat, že stroj pochopí a ocení variabilitu jazyka pouze tehdy, když jej skupina anotátorů trénuje na různých sadách řečových dat.
Dynamika v řeči
Další velkou výzvou při vývoji konverzační umělé inteligence je vnést do boje dynamiku řeči. Například při hovoru používáme několik výplní, pauz, fragmentů vět a nerozluštitelných zvuků. Řeč je navíc mnohem složitější než psané slovo, protože mezi každým slovem obvykle neděláme pauzy a nezdůrazňujeme správnou slabiku.
Když nasloucháme druhým, máme tendenci odvodit záměr a význam jejich rozhovoru pomocí našich celoživotních zkušeností. Výsledkem je, že jejich slova dáváme do kontextu a chápeme je, i když jsou nejednoznačná. Stroj však této kvality není schopen.
Hlučná data
Hlučná data nebo hluk na pozadí jsou data, která nemají hodnotu pro konverzace, jako jsou zvonky, psi, děti a další zvuky na pozadí. Proto je nezbytné čistit nebo filtrovat audio soubory těchto zvuků a trénujte systém umělé inteligence, aby identifikoval zvuky, na kterých záleží, a na kterých ne.
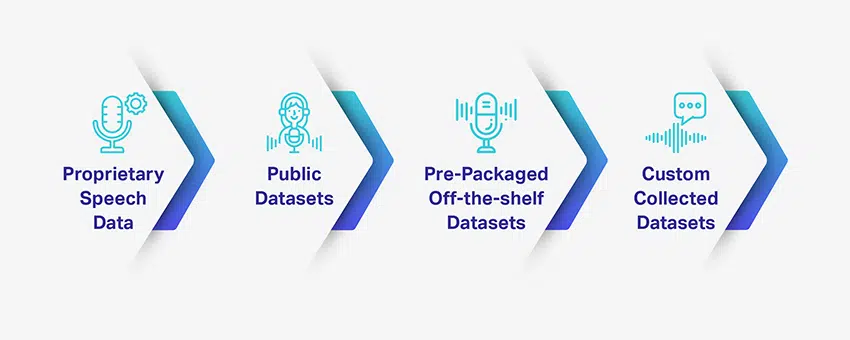
Klady a zápory různých typů dat řeči
 Vybudování systému rozpoznávání hlasu založeného na umělé inteligenci nebo konverzační umělé inteligence vyžaduje spoustu tréninkových a testovacích datových sad. Mít přístup k takto kvalitním datovým sadám – spolehlivým a splňujícím vaše specifické projektové potřeby – však není snadné. Přesto existují možnosti pro podniky, které hledají školicí datové sady, a každá možnost má své výhody a nevýhody.
Vybudování systému rozpoznávání hlasu založeného na umělé inteligenci nebo konverzační umělé inteligence vyžaduje spoustu tréninkových a testovacích datových sad. Mít přístup k takto kvalitním datovým sadám – spolehlivým a splňujícím vaše specifické projektové potřeby – však není snadné. Přesto existují možnosti pro podniky, které hledají školicí datové sady, a každá možnost má své výhody a nevýhody.
V případě, že hledáte obecný typ datové sady, máte k dispozici spoustu možností veřejné řeči. Chcete-li však něco konkrétnějšího a relevantního pro váš projektový požadavek, možná jej budete muset shromáždit a upravit sami.
Proprietární data řeči
Prvním místem, kam byste se měli podívat, by byla vlastnická data vaší společnosti. Protože však máte zákonné právo a souhlas s používáním dat řeči zákazníků, můžete být schopni použít tento rozsáhlý soubor dat pro školení a testování svých projektů.
Klady:
- Žádné další náklady na sběr dat na školení
- Údaje o školení jsou pravděpodobně relevantní pro vaši firmu
- Data řeči mají také přirozenou akustiku prostředí, dynamické uživatele a zařízení.
Nevýhody:
- Použití takových dat vás může stát spoustu peněz na povolení k záznamu a použití.
- Data řeči mohou mít jazyková, demografická nebo zákaznická omezení
- Data mohou být zdarma, ale stále budete platit za zpracování, přepis, označování a další.
Veřejné datové sady
Veřejné datové sady řeči jsou další možností, pokud nehodláte používat ty své. Tyto datové sady jsou součástí veřejné domény a lze je shromažďovat pro projekty s otevřeným zdrojovým kódem.
Klady:
- Veřejné datové sady jsou zdarma a ideální pro nízkorozpočtové projekty
- Jsou k dispozici k okamžitému stažení
- Veřejné datové sady přicházejí v různých skriptovaných a neskriptovaných vzorových sadách.
Nevýhody:
- Náklady na zpracování a zajištění kvality mohou být vysoké
- Kvalita datových sad veřejné řeči se do značné míry liší
- Nabízené ukázky řeči jsou obvykle obecné, takže nejsou vhodné pro vývoj konkrétních řečových projektů
- Datové sady jsou obvykle zaměřeny na anglický jazyk
Předem zabalené/běžné datové sady
Prozkoumat předem zabalené datové sady je další možností, pokud jsou veřejná data nebo proprietární sběr dat řeči nevyhovuje vašim potřebám.
Prodejce shromáždil předem zabalené datové sady řeči pro konkrétní účel dalšího prodeje klientům. Tento typ datové sady by mohl být použit k vývoji obecných aplikací nebo specifických účelů.
Klady:
- Můžete získat přístup k datové sadě, která vyhovuje vašim konkrétním potřebám řečových dat
- Je cenově dostupnější použít předem zabalenou datovou sadu než shromažďovat vlastní
- Možná budete moci rychle získat přístup k datové sadě
Nevýhody:
- Protože je datová sada předem zabalena, není přizpůsobena potřebám vašeho projektu.
- Navíc tato datová sada není jedinečná pro vaši společnost, protože ji může zakoupit jakýkoli jiný podnik.
Vyberte Vlastní shromážděné datové sady
Při vytváření řečové aplikace byste potřebovali trénovací datovou sadu, která splňuje všechny vaše specifické požadavky. Je však vysoce nepravděpodobné, že získáte přístup k předem zabalené datové sadě, která vyhovuje jedinečným požadavkům vašeho projektu. Jedinou dostupnou možností by bylo vytvořit svůj datový soubor nebo obstarat datový soubor prostřednictvím poskytovatelů řešení třetích stran.
Datové sady pro vaše potřeby školení a testování jsou zcela přizpůsobitelné. Můžete zahrnout jazykovou dynamiku, rozmanitost řečových dat a přístup k různým účastníkům. Kromě toho lze datovou sadu škálovat tak, aby včas vyhovovala požadavkům vašeho projektu.
Klady:
- Datové sady se shromažďují pro váš konkrétní případ použití. Možnost, že se algoritmy AI odchýlí od zamýšlených výsledků, je minimalizována.
- Kontrolujte a omezujte zkreslení dat AI
Nevýhody:
- Soubory dat mohou být nákladné a časově náročné; přínosy však vždy převažují nad náklady.

Odvětví využívající konverzační umělou inteligenci
V současné době se konverzační AI používá převážně jako Chatboti. Několik průmyslových odvětví však zavádí tuto technologii, aby získala obrovské výhody. Některá odvětví využívající konverzační AI jsou:
Zdravotní péče
 Konverzační umělá inteligence má obrovský dopad na sektor zdravotnictví. Konverzační umělá inteligence se ukázala jako přínosná pro pacienty, lékaře, personál, sestry a další zdravotnický personál.
Konverzační umělá inteligence má obrovský dopad na sektor zdravotnictví. Konverzační umělá inteligence se ukázala jako přínosná pro pacienty, lékaře, personál, sestry a další zdravotnický personál.
Některé z výhod jsou
- Zapojení pacienta ve fázi po léčbě
- Chatboti pro plánování schůzek
- Zodpovídání často kladených otázek a obecných dotazů
- Hodnocení symptomů
- Identifikujte pacienty kritické péče
- Eskalace mimořádných případů
Ecommerce
 Konverzační umělá inteligence pomáhá podnikům elektronického obchodování oslovit jejich zákazníky, poskytovat přizpůsobená doporučení a prodávat produkty.
Konverzační umělá inteligence pomáhá podnikům elektronického obchodování oslovit jejich zákazníky, poskytovat přizpůsobená doporučení a prodávat produkty.
Odvětví elektronického obchodování využívá výhod této technologie, která je nejlepší ve své třídě.
- Shromažďování informací o zákaznících
- Poskytněte relevantní informace o produktu a doporučení
- Zlepšení spokojenosti zákazníků
- Pomoc při zadávání objednávek a vracení zboží
- Odpovězte na časté dotazy
- Cross-sell a upsell produkty
Bankovnictví
 Bankovní sektor nasazuje konverzační nástroje umělé inteligence ke zlepšení interakce se zákazníky, zpracování požadavků v reálném čase a poskytování zjednodušené a jednotné zákaznické zkušenosti napříč různými kanály.
Bankovní sektor nasazuje konverzační nástroje umělé inteligence ke zlepšení interakce se zákazníky, zpracování požadavků v reálném čase a poskytování zjednodušené a jednotné zákaznické zkušenosti napříč různými kanály.
- Umožněte zákazníkům kontrolovat své zůstatky v reálném čase
- Pomoc s vklady
- Pomoc s podáním daňového přiznání a žádostí o úvěr
- Zjednodušte bankovní proces zasíláním upomínek, upozornění a upozornění
Pojištění
 Podobně jako bankovní sektor je i pojišťovnictví digitálně řízeno konverzační umělou inteligencí a sklízí její výhody. Například konverzační umělá inteligence pomáhá pojišťovnictví poskytovat rychlejší a spolehlivější prostředky pro řešení konfliktů a nároků.
Podobně jako bankovní sektor je i pojišťovnictví digitálně řízeno konverzační umělou inteligencí a sklízí její výhody. Například konverzační umělá inteligence pomáhá pojišťovnictví poskytovat rychlejší a spolehlivější prostředky pro řešení konfliktů a nároků.
- Poskytujte doporučení týkající se zásad
- Rychlejší vyřízení škod
- Eliminujte čekací doby
- Získejte zpětnou vazbu a recenze od zákazníků
- Vytvořte povědomí zákazníků o zásadách
- Spravujte rychlejší nároky a obnovení

Nabídka Shaip
Pokud jde o poskytování kvalitních a spolehlivých datových sad pro vývoj pokročilých řečových aplikací pro interakci mezi člověkem a strojem, Shaip se svými úspěšnými nasazeními vede na trhu. S akutním nedostatkem chatbotů a řečových asistentů však společnosti stále více hledají služby společnosti Shaip – lídra na trhu – k poskytování přizpůsobených, přesných a kvalitních datových sad pro školení a testování pro projekty AI.
Kombinací zpracování přirozeného jazyka můžeme poskytovat personalizované zážitky tím, že pomáháme vyvíjet přesné řečové aplikace, které efektivně napodobují lidské konverzace. K poskytování vysoce kvalitních zákaznických zkušeností používáme spoustu špičkových technologií. NLP učí stroje interpretovat lidské jazyky a komunikovat s lidmi.
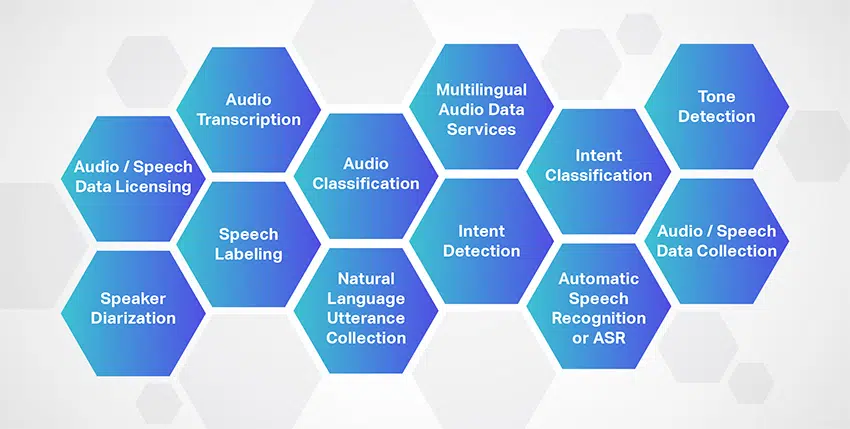
Přepis zvuku
Shaip je přední poskytovatel služeb přepisu zvuku, který nabízí různé řečové/audio soubory pro všechny typy projektů. Kromě toho Shaip nabízí 100% přepisovou službu vytvořenou lidmi pro převod audio a video souborů – rozhovorů, seminářů, přednášek, podcastů atd. do snadno čitelného textu.
Označování řeči
Shaip nabízí rozsáhlé služby označování řeči pomocí odborného oddělení zvuků a řeči ve zvukovém souboru a označení každého souboru. Přesným oddělením podobných zvukových zvuků a jejich anotací
Diarizace reproduktorů
Odbornost společnosti Sharp se rozšiřuje na nabídku vynikajících řešení diarizace reproduktorů pomocí segmentace zvukové nahrávky na základě jejich zdroje. Kromě toho jsou přesně identifikovány a klasifikovány hranice reproduktorů, jako je reproduktor 1, reproduktor 2, hudba, hluk na pozadí, zvuky vozidel, ticho a další, aby se určil počet reproduktorů.
Klasifikace zvuku
Anotace začíná klasifikací zvukových souborů do předem určených kategorií. Kategorie závisí především na požadavcích projektu a obvykle zahrnují záměr uživatele, jazyk, sémantickou segmentaci, hluk na pozadí, celkový počet mluvčích a další.
Sbírka promluvy v přirozeném jazyce / probuzení slov
Těžko předvídat, že klient bude vždy volit podobná slova při pokládání dotazu nebo iniciování požadavku. Např. "Kde je nejbližší restaurace?" „Najít restaurace v okolí“ nebo „Je v okolí restaurace?“
Všechny tři výroky mají stejný záměr, ale jsou jinak formulovány. Prostřednictvím permutace a kombinace odborníci na konverzační ai specialisty ze společnosti Shaip identifikují všechny možné kombinace pro vyjádření stejného požadavku. Shaip shromažďuje a anotuje výroky a probouzecí slova se zaměřením na sémantiku, kontext, tón, dikci, načasování, přízvuk a dialekty.
Vícejazyčné zvukové datové služby
Vícejazyčné zvukové datové služby jsou další vysoce preferovanou nabídkou od společnosti Shaip, protože máme tým sběratelů dat shromažďující zvuková data ve více než 150 jazycích a dialektech po celém světě.
Detekce záměru
Lidské interakce a komunikace jsou často komplikovanější, než jim přiznáváme. A tato vrozená komplikace ztěžuje trénování modelu ML, aby přesně porozuměl lidské řeči.
Kromě toho mohou různí lidé ze stejné demografické nebo různých demografických skupin vyjadřovat stejný záměr nebo sentiment odlišně. Systém rozpoznávání řeči tedy musí být trénován, aby rozpoznal společný záměr bez ohledu na demografickou skupinu.
Aby bylo zajištěno, že můžete trénovat a rozvíjet špičkový model ML, naši logopedi poskytují rozsáhlé a různorodé soubory dat, které pomáhají systému identifikovat několik způsobů, jak lidské bytosti vyjadřují stejný záměr.
Klasifikace záměru
Podobně jako při identifikaci stejného záměru od různých lidí by vaši chatboti měli být také vyškoleni, aby kategorizovali komentáře zákazníků do různých kategorií – předem určených vámi. Každý chatbot nebo virtuální asistent je navržen a vyvinut se specifickým účelem. Shaip může podle potřeby klasifikovat záměr uživatele do předem definovaných kategorií.
Automatické rozpoznávání řeči nebo ASR
Rozpoznávání řeči“ označuje převod mluvených slov na text; nicméně rozpoznávání hlasu a identifikace mluvčího mají za cíl identifikovat jak mluvený obsah, tak identitu mluvčího. Přesnost ASR je dána různými parametry, tj. hlasitostí reproduktoru, hlukem na pozadí, nahrávacím zařízením atd.
Detekce tónů
Dalším zajímavým aspektem lidské interakce je tón – vnitřně rozpoznáváme význam slov v závislosti na tónu, s nímž jsou vyslovena. I když to, co říkáme, je důležité, jak tato slova říkáme, také vyjadřují význam.
Například jednoduchá fráze jako „Jaká radost!“ může být zvoláním štěstí a může být také zamýšleno jako sarkastické. Záleží na tónu a stresu.
'Co to děláš?'
'Co to děláš?'
Obě tyto věty mají přesná slova, ale důraz na slova je jiný a mění celý význam vět. Chatbot je trénován, aby identifikoval štěstí, sarkasmus, hněv, podráždění a další výrazy. Zde vstupuje do hry odbornost řečových patologů a anotátorů Sharpu.
Licencování dat zvuku / řeči
Shaip nabízí nepřekonatelné standardní datové sady řeči, které lze upravit tak, aby vyhovovaly specifickým potřebám vašeho projektu. Většina našich datových sad se vejde do každého rozpočtu a data jsou škálovatelná, aby splnila všechny budoucí požadavky projektu. Nabízíme přes 40 100 hodin standardních datových sad řeči ve více než 50 dialektech ve více než XNUMX jazycích. Poskytujeme také řadu typů zvuku, včetně spontánních, monologových, skriptovaných a probouzecích slov. Zobrazit celý Katalog dat.
Sběr dat zvuku / řeči
Pokud je nedostatek kvalitních datových sad řeči, výsledné řešení řeči může být plné problémů a postrádá spolehlivost. Shaip je jedním z mála poskytovatelů, kteří dodávají vícejazyčné zvukové sbírky, přepisy zvuku a anotační nástroje a služby, které jsou plně přizpůsobitelné pro daný projekt.
Na data řeči lze nahlížet jako na spektrum, od přirozené řeči na jednom konci k nepřirozené řeči na straně druhé. V přirozené řeči máte mluvčího mluvit spontánně konverzačním způsobem. Na druhou stranu je zvuk nepřirozené řeči omezen, když mluvčí čte scénář. Nakonec jsou mluvčí vyzváni, aby vyslovovali slova nebo fráze kontrolovaným způsobem uprostřed spektra.
Odbornost společnosti Sharp se rozšiřuje na poskytování různých typů datových sad řeči ve více než 150 jazycích

































Příběhy o úspěchu
Spolupracovali jsme s některými špičkovými podniky a značkami a poskytli jsme jim konverzační řešení AI nejvyšší úrovně.
Některé z našich úspěšných příběhů zahrnují např.
- Vyvinuli jsme datovou sadu pro rozpoznávání řeči s více než 10,000 XNUMX hodinami vícejazyčných přepisů, konverzací a zvukových souborů, abychom mohli trénovat a budovat živého chatbota.
- Vytvořili jsme vysoce kvalitní datovou sadu 1000 konverzací o 6 otáčkách na konverzaci použitou pro školení pojišťovacích chatbotů.
- Náš tým více než 3000 lingvistických odborníků poskytl více než 1000 hodin zvukových souborů a přepisů ve 27 rodných jazycích pro školení a testování digitálního asistenta.
- Náš tým anotátorů a lingvistických odborníků také rychle shromáždil a dodal 20,000 27 a více hodin promluv ve více než XNUMX světových jazycích.
- Naše služby automatického rozpoznávání řeči jsou jednou z nejpreferovanějších v tomto odvětví. Poskytli jsme spolehlivě označené zvukové soubory, abychom zajistili zvláštní pozornost věnovanou výslovnosti, tónu a záměru pomocí široké škály přepisů a lexikonů z různých sad reproduktorů, abychom zlepšili spolehlivost modelů ASR.
Naše úspěšné příběhy vycházejí z odhodlání našeho týmu poskytovat našim klientům vždy ty nejlepší služby s využitím nejnovějších technologií. To, co nás odlišuje, je to, že naše práce je podporována odbornými anotátory, kteří poskytují nezaujaté a přesné datové sady anotací zlatého standardu.
Náš tým pro shromažďování dat složený z více než 30,000 XNUMX přispěvatelů může získávat, škálovat a poskytovat vysoce kvalitní datové sady, které napomáhají rychlému nasazení modelů ML. Kromě toho pracujeme na nejnovější platformě založené na umělé inteligenci a jsme schopni poskytovat firmám zrychlená řešení řečových dat mnohem rychleji než naši nejbližší konkurenti.
