
Klíč k překonání překážek rozvoje AI: Spolehlivější data
Dnes má průměrný člověk v kapse milionkrát větší výpočetní výkon, než musela NASA provést při přistání na Měsíci v roce 1969. Stejné všudypřítomné zařízení, které pohodlně demonstruje množství výpočetního výkonu, splňuje také další předpoklad zlatého věku AI: množství dat. Podle poznatků z Information Overload Research Group bylo za poslední dva roky vytvořeno 90% světových dat. Nyní, když exponenciální růst výpočetního výkonu konečně konvergoval se stejně meteorickým růstem v generování dat, inovace dat v oblasti AI explodují natolik, že si někteří odborníci myslí, že nastartují čtvrtou průmyslovou revoluci.
Data z Národní asociace rizikového kapitálu naznačují, že v odvětví umělé inteligence došlo v prvním čtvrtletí roku 6.9 k rekordním investicím ve výši 2020 miliardy USD. Není těžké vidět potenciál nástrojů umělé inteligence, protože se již využívá všude kolem nás. Mezi viditelnější případy použití produktů AI patří motory doporučení za našimi oblíbenými aplikacemi, jako jsou Spotify a Netflix. I když je zábavné objevovat nového umělce, který chcete poslouchat, nebo novou televizní show, kde se můžete dívat na binge, tyto implementace jsou poměrně nízké. Ostatní algoritmy hodnotí výsledky testů - částečně určují, kde jsou studenti přijímáni na vysokou školu - a ještě jiní prosívají životopisy kandidátů a rozhodují, kteří uchazeči získají konkrétní práci. Některé nástroje umělé inteligence mohou mít dokonce důsledky na život nebo na smrt, například model umělé inteligence, který sleduje rakovinu prsu (který předčí lékaře).
Navzdory stálému růstu v reálných příkladech vývoje AI a počtu začínajících podniků, které se snaží vytvořit novou generaci transformačních nástrojů, zůstávají problémy s účinným vývojem a implementací. Zejména je výstup AI jen tak přesný, jak to vstup umožňuje, což znamená, že kvalita je prvořadá.

Navigace v komplexních požadavcích na dodržování předpisů
Jako by hledání kvalitních dat nebylo dost obtížné, některá průmyslová odvětví, která mohou z inovací dat o umělé inteligenci těžit nejvíce, jsou také nejvíce regulována. Zdravotnictví je možná nejlepším příkladem, a přestože průzkum HIT Infrastructure zjistil, že 91% zasvěcených z průmyslu si myslí, že technologie by mohla zlepšit přístup k péči, tento optimismus je zmírněn skutečností, že 75% to považuje za ohrožení bezpečnosti a soukromí pacientů - a pacienti nejsou jediní v ohrožení.
Rozsáhlé předpisy přijaté zákonem o přenositelnosti a odpovědnosti v oblasti zdravotního pojištění se nyní protínají s různými místními překážkami dodržování údajů, jako je evropské obecné nařízení o ochraně údajů, kalifornský zákon o ochraně osobních údajů ve Spojených státech a zákon o ochraně osobních údajů v Singapuru. K těmto místním předpisům se připojí ještě mnoho dalších, a protože se telehealth stává významnějším zdrojem údajů o zdravotní péči, je pravděpodobné, že předpisy získají ještě pevnější uchopení údajů o pacientech při přepravě. Výsledkem je, že bezpečná a vyhovující cloudová platforma společnosti Shaip bude ještě cennějším prostředkem pro shromažďování a přístup ke zdravotnickým datům pro výcvik produktů AI.
Osobně identifikovatelné informace mohou být významnou hrozbou pro váš vývoj AI, ale i zcela kompatibilní implementace je v ohrožení, pokud nemůže přinést takové přesné výsledky, jaké přicházejí pouze s různými daty o školení. Studie z roku 2020 v časopise Journal of the American Medical Association prokázala, že algoritmy strojového učení v lékařské oblasti jsou nejčastěji trénovány na datech od pacientů v Kalifornii, New Yorku a Massachusetts. Vzhledem k tomu, že tito pacienti představují méně než pětinu americké populace, nemluvě o zbytku světa, je těžké si představit, jak by tyto modely mohly přinést cokoli jiného než zkreslené výsledky.

 Společnost Shaip uznává potíže se zabezpečením vyhovujících geograficky rozmanitých informací a nabízí licencovaná data zdravotní péče z celé řady regionů, které jsou speciálně upraveny s cílem vytvořit přesné algoritmy. Tato data přicházejí ve formě textu, jako jsou lékařské záznamy nebo informace o pohledávkách, lékařské diagnostické zobrazování, jako jsou CT, audio, jako jsou mluvené poznámky od lékařů nebo rozhovory mezi lékaři a pacienty, a dokonce i video z výsledků MRI. Je také zcela deidentifikován a anonymizován a chrání vaši organizaci před etickými i finančními důsledky, které mohou následovat po porušení kteréhokoli ze zvyšujícího se počtu předpisů, které upravují údaje domácího i mezinárodního původu.
Společnost Shaip uznává potíže se zabezpečením vyhovujících geograficky rozmanitých informací a nabízí licencovaná data zdravotní péče z celé řady regionů, které jsou speciálně upraveny s cílem vytvořit přesné algoritmy. Tato data přicházejí ve formě textu, jako jsou lékařské záznamy nebo informace o pohledávkách, lékařské diagnostické zobrazování, jako jsou CT, audio, jako jsou mluvené poznámky od lékařů nebo rozhovory mezi lékaři a pacienty, a dokonce i video z výsledků MRI. Je také zcela deidentifikován a anonymizován a chrání vaši organizaci před etickými i finančními důsledky, které mohou následovat po porušení kteréhokoli ze zvyšujícího se počtu předpisů, které upravují údaje domácího i mezinárodního původu.
Překonávání překážek rozvoje AI
Úsilí o rozvoj umělé inteligence zahrnuje významné překážky bez ohledu na to, v jakém odvětví se nacházejí, a proces přechodu od proveditelného nápadu k úspěšnému produktu je plný obtíží. Mezi výzvami získávání správných dat a potřebou anonymizovat je, aby byly v souladu se všemi příslušnými předpisy, se může cítit, že je to skutečně konstrukce a školení algoritmu.
Chcete-li dát vaší organizaci všechny výhody nezbytné ve snaze navrhnout průkopnický nový vývoj umělé inteligence, měli byste zvážit partnerství se společností, jako je Shaip. Chetan Parikh a Vatsal Ghiya založili společnost Shaip, aby pomohli společnostem připravit řešení, která by mohla změnit zdravotní péči v USA. Po více než 16 letech v podnikání se naše společnost rozrostla o více než 600 členů týmu a spolupracovali jsme se stovkami zákazníci přeměňují přesvědčivé nápady na řešení AI.
S našimi lidmi, procesy a platformou pracující pro vaši organizaci můžete okamžitě odemknout následující čtyři výhody a katapultovat váš projekt k úspěšnému dokončení:
1. Schopnost osvobodit vědce v oblasti dat
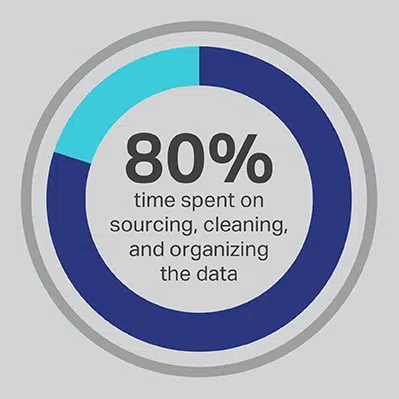
Nelze obejít, že proces vývoje AI vyžaduje značné investice času, ale vždy můžete optimalizovat funkce, které váš tým tráví nejvíce času prováděním. Najali jste své datové vědce, protože jsou odborníky na vývoj pokročilých algoritmů a modelů strojového učení, ale výzkum důsledně ukazuje, že tito pracovníci skutečně tráví 80% času získáváním, čištěním a organizováním dat, která budou projekt pohánět. Více než tři čtvrtiny (76%) vědců uvádějí, že tyto pozemské procesy sběru dat jsou také jejich nejméně oblíbenými částmi v práci, ale potřeba kvalitních dat zbývá jen 20% jejich času na skutečný vývoj, což je nejzajímavější a intelektuálně podnětnější práce pro mnoho datových vědců. Prostřednictvím získávání dat prostřednictvím dodavatele třetích stran, jako je Shaip, může společnost nechat své drahé a talentované datové inženýry outsourcovat svou práci jako správci dat a místo toho trávit čas částmi řešení AI, kde mohou produkovat největší hodnotu.
2. Schopnost dosáhnout lepších výsledků
 Mnoho vedoucích pro vývoj umělé inteligence se rozhodne ke snížení nákladů použít data typu open-source nebo crowdsourcing, ale toto rozhodnutí z dlouhodobého hlediska téměř vždy skončí dražší. Tyto typy dat jsou snadno dostupné, ale nemohou odpovídat kvalitě pečlivě sestavených datových sad. Data Crowdsourced jsou obzvláště bohatá na chyby, opomenutí a nepřesnosti, a zatímco tyto problémy mohou být někdy během procesu vývoje vyřešeny pod dohledem vašich techniků, vyžadují další iterace, které by nebyly nutné, pokud byste začali s vyššími -kvalitní data od začátku.
Mnoho vedoucích pro vývoj umělé inteligence se rozhodne ke snížení nákladů použít data typu open-source nebo crowdsourcing, ale toto rozhodnutí z dlouhodobého hlediska téměř vždy skončí dražší. Tyto typy dat jsou snadno dostupné, ale nemohou odpovídat kvalitě pečlivě sestavených datových sad. Data Crowdsourced jsou obzvláště bohatá na chyby, opomenutí a nepřesnosti, a zatímco tyto problémy mohou být někdy během procesu vývoje vyřešeny pod dohledem vašich techniků, vyžadují další iterace, které by nebyly nutné, pokud byste začali s vyššími -kvalitní data od začátku.
Spoléhání se na data typu open-source je další běžná zkratka, která přichází s vlastní sadou nástrah. Nedostatečná diferenciace je jedním z největších problémů, protože algoritmus trénovaný pomocí dat z otevřeného zdroje je snadněji replikován než ten, který je postaven na licencovaných datových sadách. Tím, že půjdete touto cestou, zvete konkurenci dalších účastníků v prostoru, kteří by mohli kdykoli podkopat vaše ceny a získat podíl na trhu. Když se spoléháte na Shaipa, máte přístup k nejkvalitnějším datům shromážděným kvalifikovanou spravovanou pracovní silou a my vám můžeme udělit exkluzivní licenci na vlastní datovou sadu, která brání konkurentům ve snadném obnovení vašeho těžce získaného duševního vlastnictví.
3. Přístup ke zkušeným profesionálům
 I když váš interní seznam zahrnuje zkušené inženýry a talentované datové vědce, vaše nástroje AI mohou těžit z moudrosti, která vychází pouze ze zkušeností. Naši odborníci na tematické okruhy stojí v čele řady implementací AI ve svých oborech a během toho se naučili cenné lekce a jejich jediným cílem je pomoci vám dosáhnout toho vašeho.
I když váš interní seznam zahrnuje zkušené inženýry a talentované datové vědce, vaše nástroje AI mohou těžit z moudrosti, která vychází pouze ze zkušeností. Naši odborníci na tematické okruhy stojí v čele řady implementací AI ve svých oborech a během toho se naučili cenné lekce a jejich jediným cílem je pomoci vám dosáhnout toho vašeho.
S odborníky na doménu, kteří pro vás identifikují, organizují, kategorizují a označují data, víte, že informace použité k trénování vašeho algoritmu mohou přinést nejlepší možné výsledky. Pravidelně také zajišťujeme kvalitu, abychom zajistili, že data splňují nejvyšší standardy a budou fungovat tak, jak bylo zamýšleno nejen v laboratoři, ale také v reálné situaci.
4. Zrychlená časová osa vývoje
K vývoji AI nedochází přes noc, ale může se to stát rychleji, když uzavřete partnerství se Shaipem. In-house sběr dat a anotace vytváří významné provozní úzké místo, které drží zbytek procesu vývoje. Spolupráce se společností Shaip vám poskytuje okamžitý přístup k naší rozsáhlé knihovně dat připravených k použití a naši odborníci budou schopni získat jakékoli další vstupy, které potřebujete, s našimi hlubokými znalostmi oboru a globální sítí. Bez zátěže získávání zdrojů a anotací se váš tým může hned pustit do práce na skutečném vývoji a náš tréninkový model může pomoci identifikovat časné nepřesnosti, aby se snížily iterace nezbytné ke splnění cílů přesnosti.
Pokud nejste připraveni outsourcovat všechny aspekty správy dat, Shaip také nabízí cloudovou platformu, která pomáhá týmům efektivněji vytvářet, upravovat a anotovat různé typy dat, včetně podpory obrázků, videa, textu a zvuku . ShaipCloud obsahuje celou řadu intuitivních nástrojů pro ověřování a pracovní postupy, jako je patentované řešení pro sledování a monitorování pracovní zátěže, nástroj pro přepis pro přepis složitých a obtížných zvukových záznamů a součást kontroly kvality pro zajištění nekompromisní kvality. Nejlepší ze všeho je, že je škálovatelný, takže může růst, jak se zvyšují různé požadavky vašeho projektu.
Věk inovací v oblasti umělé inteligence teprve začíná a v nadcházejících letech uvidíme neuvěřitelné pokroky a inovace, které mají potenciál přetvořit celé průmyslové odvětví nebo dokonce změnit společnost jako celek. Ve společnosti Shaip chceme využít své odborné znalosti, abychom sloužili jako transformační síla a pomohli nejrevolučnějším společnostem na světě využít sílu řešení AI k dosažení ambiciózních cílů.
Máme hluboké zkušenosti s aplikacemi ve zdravotnictví a konverzační AI, ale máme také potřebné dovednosti k trénování modelů pro téměř jakýkoli druh aplikace. Další informace o tom, jak může společnost Shaip pomoci vašemu projektu od nápadu po implementaci, najdete v mnoha zdrojích dostupných na našem webu nebo nás můžete kontaktovat ještě dnes.
