




Posílení zdravotní péče pomocí generativní umělé inteligence: Revoluční diagnostika a léčba
Umělá inteligence (AI) v posledních letech výrazně pokročila v různých odvětvích a výjimkou není ani zdravotnictví. Generativní AI, podmnožina zaměřená na AI
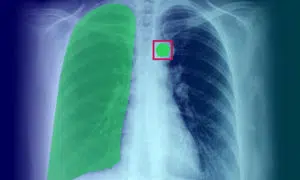
Anotace lékařského snímku: Definice, aplikace, případy použití a typy
Anotace lékařských snímků hraje zásadní roli při poskytování nezbytných školicích dat algoritmům strojového učení a modelům AI. Tento proces je nezbytný pro

Etika a zaujatost: Orientace ve výzvách spolupráce člověka a umělé inteligence při hodnocení modelů
Ve snaze využít transformační sílu umělé inteligence (AI) čelí technologická komunita zásadní výzvě: zajištění etické integrity a minimalizace zaujatosti.

The Human Touch: Zlepšení kreativity umělé inteligence pomocí subjektivního hodnocení
V rychle se vyvíjejícím světě umělé inteligence (AI) už není honba za kreativitou jen lidským úsilím. Dnešní technologie umělé inteligence se lámou

Maximalizace relevance vyhledávání pomocí označování dat: Tipy a osvědčené postupy
Uživatelé jsou dnes ponořeni do obrovského množství informací, takže hledání informací, které potřebují, je složité. Relevance vyhledávání měří přesnost informací an

Bridging the Gap: Integrace lidské intuice do hodnocení modelu AI
Úvod V době, kdy umělá inteligence (AI) utváří každý aspekt našeho života, se integrace lidské intuice do hodnocení modelů umělé inteligence objevuje jako

Nejlepší datové sady pro zdravotnictví s otevřeným zdrojovým kódem pro projekty strojového učení
Globální systém zdravotní péče denně produkuje obrovské množství lékařských dat, která mají potenciál být využita pro aplikace strojového učení.

Navigace v ochraně osobních údajů v AI: Strategie pro dodržování předpisů a inovace
Úvod V rychle se vyvíjejícím prostředí umělé inteligence (AI) čelí společnosti jako OpenAI významným výzvám při hledání rovnováhy mezi neukojitelnou potřebou dat a přísnými
Budoucnost dat s inteligentním rozpoznáváním znaků (ICR)
Ručně psané poznámky mají zvláštní kouzlo i v našem digitálním světě. Inteligentní rozpoznávání znaků (ICR) pomáhá překlenout analogovou a digitální propast a převádí ručně psaný text

Vliv NLP na diagnostiku ve zdravotnictví
Zpracování přirozeného jazyka (NLP) mění způsob, jakým pracujeme s technologií. Zpracovává lidskou řeč, aby odemkl obrovský informační potenciál. Technologie má stejný potenciál

Výběr správné datové sady pro rozpoznávání řeči pro váš model umělé inteligence
Představte si interakci se Siri nebo Alexou. Jejich schopnost porozumět naší řeči je fascinující. Tato schopnost vychází z datových sad používaných při jejich školení. Tyto

Datové sady pro zdravotnictví: Požehnání pro AI pro zdravotnictví
Umělá inteligence, termín, který se kdysi používal převážně ve sci-fi, je nyní realitou, která pohání růst různých průmyslových odvětví. Strategické poradenství dalšího tahu

Posílení učení s lidskou zpětnou vazbou: Definice a kroky
Posílení učení (RL) je druh strojového učení. V tomto přístupu se algoritmy učí rozhodovat pomocí pokusů a omylů, podobně jako to dělají lidé.

Příčiny halucinací AI (a techniky k jejich snížení)
Halucinace umělé inteligence se týkají případů, kdy modely umělé inteligence, zejména velké jazykové modely (LLM), generují informace, které se zdají být pravdivé, ale jsou nesprávné nebo nesouvisejí s

Co je klinická validace? Váš průvodce osvědčenými postupy a procesy
Představte si scénář, kdy je vyvinut nový diagnostický nástroj. Lékaři jsou z jeho potenciálu nadšení. Přesto, než to začlení do běžné péče, oni

Význam etické AI / Spravedlivá AI a typy předsudků, kterým je třeba se vyhnout
V rozvíjejícím se oboru umělé inteligence (AI) je zaměření na etické úvahy a spravedlnost více než morální imperativ – je to základní nutnost pro

Shrnutí lékařských záznamů AI: Definice, výzvy a osvědčené postupy
Růst lékařských záznamů ve zdravotnictví se stal výzvou i příležitostí. Představte si svět, kde každý detail v a

Abstrakce klinických dat: Definice, Proces a další
Nemocnice a kliniky se každoročně setkávají s tisíci pacientů. To vyžaduje obrovské množství oddaných lékařů a sester. Neúnavně pracují na poskytování péče

Syntetická data ve zdravotnictví: definice, přínosy a výzvy
Představte si scénář, kdy výzkumníci vyvíjejí nový lék. Potřebují rozsáhlé údaje o pacientech pro testování, ale existují značné obavy o soukromí a

Stanovení experta HIPAA pro deidentifikace
Zákon HIPAA (Health Insurance Portability and Accountability Act) nastavuje standard pro ochranu dat pacientů ve zdravotnictví. Zásadním aspektem je deidentifikace chráněného

Průkopník onkologického výzkumu s NLP: The Shaip Breakthrough
Stáhnout případovou studii Ve snaze porazit rakovinu jsou data stejně důležitá jako odhodlání. V Shaip jsme hrdí na to, že jsme umožnili velký skok
Síla zpracování přirozeného jazyka (NLP) v radiologii: Zlepšení diagnostiky a účinnosti
Radiologie hraje ve zdravotnictví zásadní roli. K diagnostice a léčbě různých stavů využívá zobrazovací techniky, jako je CT vyšetření, rentgenové záření a MRI. Přirozený jazyk

Role zpracování přirozeného jazyka (NLP) v onkologii
Rakovina představuje celosvětově významnou zdravotní výzvu. Stává se to, když buňky rostou a šíří se nekontrolovaným způsobem. Je to druhá nejčastější příčina úmrtí

Vše, co potřebujete vědět o posilování Učení z lidské zpětné vazby
V roce 2023 došlo k masivnímu nárůstu zavádění nástrojů umělé inteligence, jako je ChatGPT. Tento nárůst vyvolal živou debatu a lidé diskutují o výhodách umělé inteligence,

Síla umělé inteligence v automobilovém průmyslu
Pokud jde o integraci umělé inteligence do automobilů, stojí svět na pozoruhodné křižovatce. Představte si, že jedete po rušné silnici s umělou inteligencí a řídíte se

Výhody převodu textu na řeč v různých odvětvích
Technologie Text-to-speech (TTS) je inovativní řešení, které převádí psaný text na mluvená slova. Stala se změnou hry v několika odvětvích a způsobila revoluci

A až Z anotace dat
Průvodce pro začátečníky anotací dat: Tipy a osvědčené postupy Průvodce konečnými kupujícími pro rok 2024 Tabulka indexů Úvod Co je strojové učení? co je

Průvodce deidentifikace dat: Vše, co začátečník potřebuje vědět (v roce 2024)
Ve věku digitální transformace zdravotnické organizace rychle přesouvají své operace na digitální platformy. To sice přináší efektivitu a zjednodušené procesy, ale také

Generativní umělá inteligence ve zdravotnictví: Aplikace, výhody, výzvy a budoucí trendy
Zdravotnictví bylo vždy oblastí, kde jsou inovace oceňovány a rozhodující pro záchranu životů. Navzdory technologickému pokroku čelí zdravotnický průmysl stále přetrvávajícím výzvám.

Rozdíl mezi odpovědnou AI a etickou AI
Očekává se, že rychle rostoucí globální trh s umělou inteligencí dosáhne v roce 1847 2030 XNUMX miliard dolarů. Umělá inteligence se dostává do popředí zájmu našich životů a víme, jaký



















Posílení zdravotní péče pomocí generativní umělé inteligence: Revoluční diagnostika a léčba
Umělá inteligence (AI) v posledních letech výrazně pokročila v různých odvětvích a výjimkou není ani zdravotnictví. Generativní AI, podmnožina zaměřená na AI
Anotace lékařského snímku: Definice, aplikace, případy použití a typy
Anotace lékařských snímků hraje zásadní roli při poskytování nezbytných školicích dat algoritmům strojového učení a modelům AI. Tento proces je nezbytný pro
Etika a zaujatost: Orientace ve výzvách spolupráce člověka a umělé inteligence při hodnocení modelů
Ve snaze využít transformační sílu umělé inteligence (AI) čelí technologická komunita zásadní výzvě: zajištění etické integrity a minimalizace zaujatosti.
The Human Touch: Zlepšení kreativity umělé inteligence pomocí subjektivního hodnocení
V rychle se vyvíjejícím světě umělé inteligence (AI) už není honba za kreativitou jen lidským úsilím. Dnešní technologie umělé inteligence se lámou
Maximalizace relevance vyhledávání pomocí označování dat: Tipy a osvědčené postupy
Uživatelé jsou dnes ponořeni do obrovského množství informací, takže hledání informací, které potřebují, je složité. Relevance vyhledávání měří přesnost informací an
Bridging the Gap: Integrace lidské intuice do hodnocení modelu AI
Úvod V době, kdy umělá inteligence (AI) utváří každý aspekt našeho života, se integrace lidské intuice do hodnocení modelů umělé inteligence objevuje jako
Nejlepší datové sady pro zdravotnictví s otevřeným zdrojovým kódem pro projekty strojového učení
Globální systém zdravotní péče denně produkuje obrovské množství lékařských dat, která mají potenciál být využita pro aplikace strojového učení.
Navigace v ochraně osobních údajů v AI: Strategie pro dodržování předpisů a inovace
Úvod V rychle se vyvíjejícím prostředí umělé inteligence (AI) čelí společnosti jako OpenAI významným výzvám při hledání rovnováhy mezi neukojitelnou potřebou dat a přísnými
Budoucnost dat s inteligentním rozpoznáváním znaků (ICR)
Ručně psané poznámky mají zvláštní kouzlo i v našem digitálním světě. Inteligentní rozpoznávání znaků (ICR) pomáhá překlenout analogovou a digitální propast a převádí ručně psaný text
Vliv NLP na diagnostiku ve zdravotnictví
Zpracování přirozeného jazyka (NLP) mění způsob, jakým pracujeme s technologií. Zpracovává lidskou řeč, aby odemkl obrovský informační potenciál. Technologie má stejný potenciál
Výběr správné datové sady pro rozpoznávání řeči pro váš model umělé inteligence
Představte si interakci se Siri nebo Alexou. Jejich schopnost porozumět naší řeči je fascinující. Tato schopnost vychází z datových sad používaných při jejich školení. Tyto
Datové sady pro zdravotnictví: Požehnání pro AI pro zdravotnictví
Umělá inteligence, termín, který se kdysi používal převážně ve sci-fi, je nyní realitou, která pohání růst různých průmyslových odvětví. Strategické poradenství dalšího tahu
Posílení učení s lidskou zpětnou vazbou: Definice a kroky
Posílení učení (RL) je druh strojového učení. V tomto přístupu se algoritmy učí rozhodovat pomocí pokusů a omylů, podobně jako to dělají lidé.
Příčiny halucinací AI (a techniky k jejich snížení)
Halucinace umělé inteligence se týkají případů, kdy modely umělé inteligence, zejména velké jazykové modely (LLM), generují informace, které se zdají být pravdivé, ale jsou nesprávné nebo nesouvisejí s
Co je klinická validace? Váš průvodce osvědčenými postupy a procesy
Představte si scénář, kdy je vyvinut nový diagnostický nástroj. Lékaři jsou z jeho potenciálu nadšení. Přesto, než to začlení do běžné péče, oni
Význam etické AI / Spravedlivá AI a typy předsudků, kterým je třeba se vyhnout
V rozvíjejícím se oboru umělé inteligence (AI) je zaměření na etické úvahy a spravedlnost více než morální imperativ – je to základní nutnost pro
Shrnutí lékařských záznamů AI: Definice, výzvy a osvědčené postupy
Růst lékařských záznamů ve zdravotnictví se stal výzvou i příležitostí. Představte si svět, kde každý detail v a
Abstrakce klinických dat: Definice, Proces a další
Nemocnice a kliniky se každoročně setkávají s tisíci pacientů. To vyžaduje obrovské množství oddaných lékařů a sester. Neúnavně pracují na poskytování péče
Syntetická data ve zdravotnictví: definice, přínosy a výzvy
Představte si scénář, kdy výzkumníci vyvíjejí nový lék. Potřebují rozsáhlé údaje o pacientech pro testování, ale existují značné obavy o soukromí a
Stanovení experta HIPAA pro deidentifikace
Zákon HIPAA (Health Insurance Portability and Accountability Act) nastavuje standard pro ochranu dat pacientů ve zdravotnictví. Zásadním aspektem je deidentifikace chráněného
Průkopník onkologického výzkumu s NLP: The Shaip Breakthrough
Stáhnout případovou studii Ve snaze porazit rakovinu jsou data stejně důležitá jako odhodlání. V Shaip jsme hrdí na to, že jsme umožnili velký skok
Síla zpracování přirozeného jazyka (NLP) v radiologii: Zlepšení diagnostiky a účinnosti
Radiologie hraje ve zdravotnictví zásadní roli. K diagnostice a léčbě různých stavů využívá zobrazovací techniky, jako je CT vyšetření, rentgenové záření a MRI. Přirozený jazyk
Role zpracování přirozeného jazyka (NLP) v onkologii
Rakovina představuje celosvětově významnou zdravotní výzvu. Stává se to, když buňky rostou a šíří se nekontrolovaným způsobem. Je to druhá nejčastější příčina úmrtí
Vše, co potřebujete vědět o posilování Učení z lidské zpětné vazby
V roce 2023 došlo k masivnímu nárůstu zavádění nástrojů umělé inteligence, jako je ChatGPT. Tento nárůst vyvolal živou debatu a lidé diskutují o výhodách umělé inteligence,
Síla umělé inteligence v automobilovém průmyslu
Pokud jde o integraci umělé inteligence do automobilů, stojí svět na pozoruhodné křižovatce. Představte si, že jedete po rušné silnici s umělou inteligencí a řídíte se
Výhody převodu textu na řeč v různých odvětvích
Technologie Text-to-speech (TTS) je inovativní řešení, které převádí psaný text na mluvená slova. Stala se změnou hry v několika odvětvích a způsobila revoluci
A až Z anotace dat
Průvodce pro začátečníky anotací dat: Tipy a osvědčené postupy Průvodce konečnými kupujícími pro rok 2024 Tabulka indexů Úvod Co je strojové učení? co je
Průvodce deidentifikace dat: Vše, co začátečník potřebuje vědět (v roce 2024)
Ve věku digitální transformace zdravotnické organizace rychle přesouvají své operace na digitální platformy. To sice přináší efektivitu a zjednodušené procesy, ale také
Generativní umělá inteligence ve zdravotnictví: Aplikace, výhody, výzvy a budoucí trendy
Zdravotnictví bylo vždy oblastí, kde jsou inovace oceňovány a rozhodující pro záchranu životů. Navzdory technologickému pokroku čelí zdravotnický průmysl stále přetrvávajícím výzvám.
Rozdíl mezi odpovědnou AI a etickou AI
Očekává se, že rychle rostoucí globální trh s umělou inteligencí dosáhne v roce 1847 2030 XNUMX miliard dolarů. Umělá inteligence se dostává do popředí zájmu našich životů a víme, jaký

Co je NLP? Jak to funguje, výhody, výzvy, příklady
Stáhnout infografiku Co je to NLP? Zpracování přirozeného jazyka (NLP) je podobor umělé inteligence (AI). Umožňuje robotům analyzovat a porozumět lidské řeči,

OCR – definice, výhody, výzvy a případy použití [infografika]
OCR je technologie, která umožňuje strojům číst tištěný text a obrázky. Často se používá v podnikových aplikacích, jako je digitalizace dokumentů pro ukládání nebo zpracování, a ve spotřebitelských aplikacích, jako je skenování účtenek pro náhradu výdajů.

Stav konverzační AI 2022
Stav konverzační AI 2022 Co je to konverzační AI? Programatický a inteligentní způsob nabízení konverzačního zážitku tomimické konverzace se skutečnými lidmi prostřednictvím digitálních a telekomunikačních služeb

Co je sběr dat? Vše, co začátečník potřebuje vědět
Inteligentní modely #AI/ #ML jsou všude, ať už jsou to modely prediktivní zdravotní péče, proaktivní diagnostika,

Co je označování dat? Vše, co musí začátečník vědět
Stáhněte si Infographics Inteligentní modely AI je třeba důkladně vyškolit, aby bylo možné identifikovat vzory, objekty a případně se spolehlivě rozhodovat. Nicméně vyškolení