


Páry otázek a odpovědí
Shrnutí textu
Titulky obrázků
Generování zvuku
LLM hodnocení dat
Porovnání dat LLM
Vytváření syntetického dialogu
Shrnutí obrázků, hodnocení a ověření
Páry otázek a odpovědí
Vytvoření páru Q/A
Vytvoření klíčového slova
Sekvenční otázky a odpovědi
RAG Q/A Validace
Vytvoření páru Q/A

Vytvoření klíčového slova

Sekvenční otázky a odpovědi

RAG Q/A Validace

Shrnutí textu
Para Sumarizace
Emailová sumarizace
Shrnutí konverzace
Para Sumarizace

Emailová sumarizace
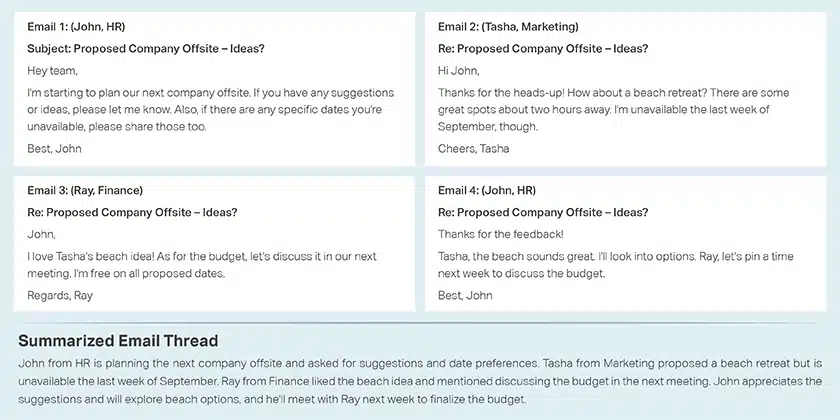
Shrnutí konverzace
Titulky obrázků

Generování zvuku

LLM hodnocení dat

Porovnání dat LLM

Vytváření syntetického dialogu
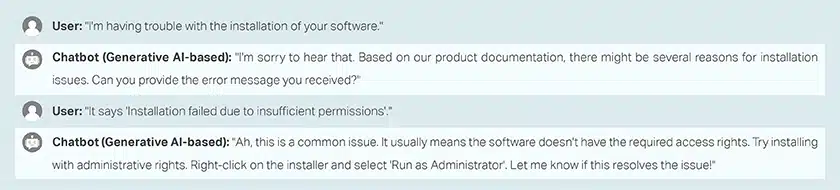
Otázky a odpovědi na školení chatbotů
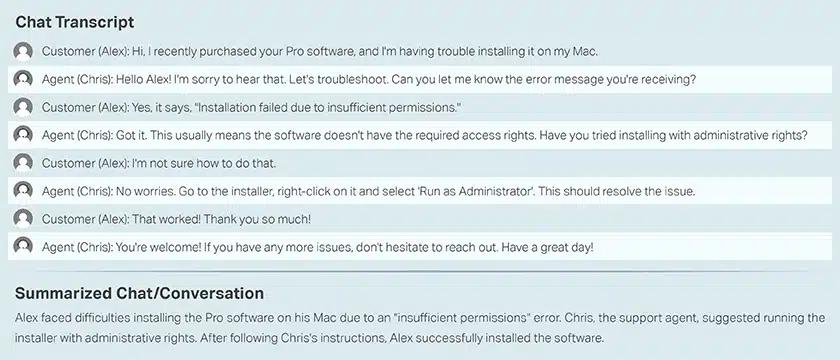
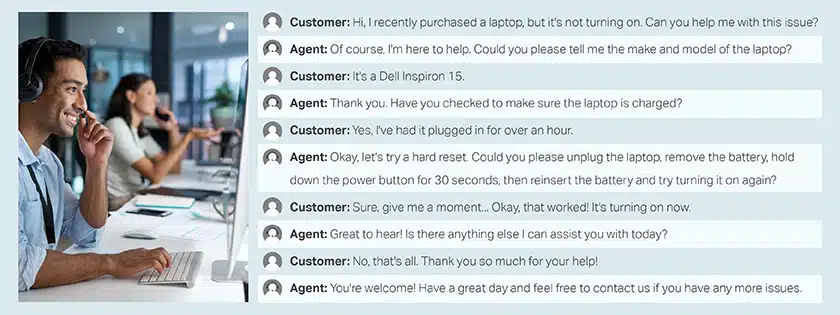
Call Center Konverzace se zákazníkem a agentem
Otázky a odpovědi na školení chatbotů
Call Center Konverzace se zákazníkem a agentem
Shrnutí obrázků, hodnocení a ověření
Hodnocení obrázku
Ověření obrázku
Shrnutí obrázků
Hodnocení obrázku
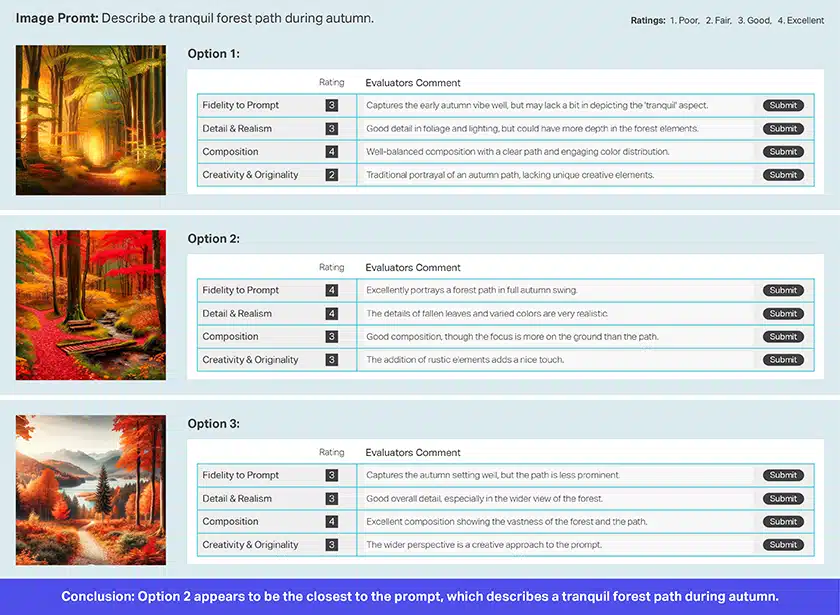
Ověření obrázku
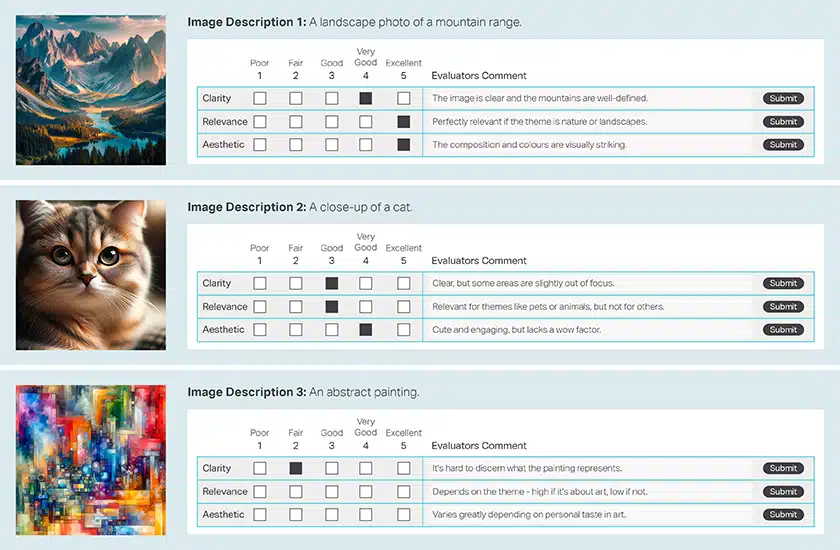
Shrnutí obrázků




Vytvoření klinického NLP je zásadní úkol, jehož řešení vyžaduje obrovskou odbornost. Jasně vidím, že jste v této oblasti o několik let před Googlem. Chci s tebou pracovat a rozšiřovat tě.
Google, Inc. Ředitel
Můj vývojový tým pracoval s Shaipovým týmem po dobu více než 2 let při vývoji rozhraní API pro zdravotní péči. Byli jsme ohromeni jejich prací provedenou v NLP specifické pro zdravotnictví a tím, čeho jsou schopni dosáhnout pomocí komplexních datových sad.
Google, Inc. Vedoucí inženýrství