



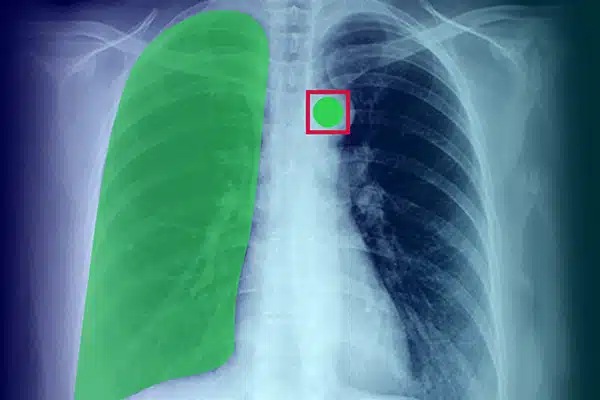
Anotace obrázku
Vylepšete lékařskou AI anotací vizuálních dat z rentgenových snímků, CT skenů a MRI. Zajistěte, aby modely umělé inteligence fungovaly excelentně v diagnostice a léčbě, a to na základě expertního označování dat. Získejte lepší výsledky pacientů díky vynikajícím náhledům na zobrazování.
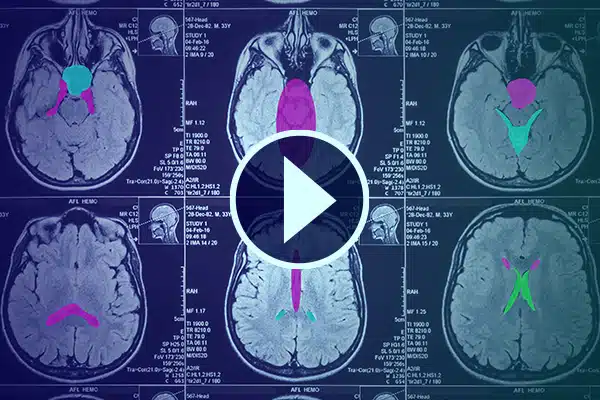
Video anotace
Pokročilá umělá inteligence ve zdravotnictví s podrobnou anotací videa. Vylepšete učení AI pomocí klasifikací a segmentací v lékařských záběrech. Vylepšete svou chirurgickou umělou inteligenci a monitorování pacienta pro lepší poskytování zdravotní péče a diagnostiku.
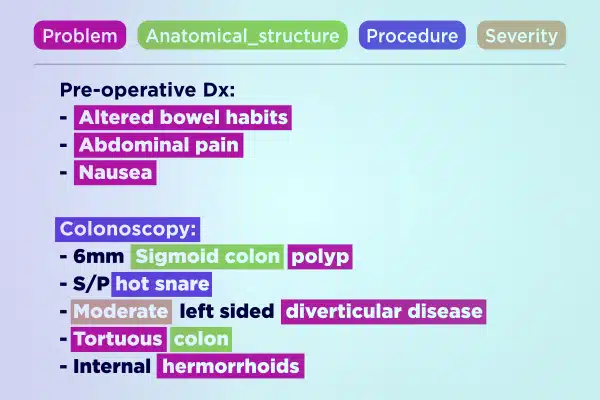
Textová anotace
Zefektivněte vývoj lékařské umělé inteligence pomocí odborně anotovaných textových dat. Rychle analyzujte a obohacujte rozsáhlé objemy textu, od ručně psaných poznámek až po zprávy o pojištění. Zajistěte přesné a použitelné informace o pokroku ve zdravotnictví.

Zvuková anotace
Využijte odbornost NLP k přesné anotaci a označení lékařských zvukových dat. Vytvářejte hlasově podporované systémy pro bezproblémové klinické operace a integrujte AI do různých hlasem aktivovaných zdravotnických produktů. Zvyšte přesnost diagnostiky pomocí odborného zpracování zvukových dat.

Lékařské kódování
Zefektivněte zdravotnickou dokumentaci tím, že ji převedete na univerzální kódy s lékařským kódováním AI. Zajistěte přesnost, zvyšte efektivitu účtování a podpořte bezproblémové poskytování zdravotních služeb pomocí špičkové asistence umělé inteligence při kódování lékařských záznamů.

Fáze 1: Odbornost v technické oblasti (pochopte rozsah a pokyny pro anotace)

Fáze 2: Školení vhodných zdrojů pro projekt

Fáze 3: Cyklus zpětné vazby a kontrola kvality anotovaných dokumentů
Radiologie
Naše služba anotací radiologických snímků zdokonaluje diagnostiku AI a zahrnuje další úroveň odborných znalostí. Každý rentgen, MRI a CT sken je pečlivě označen a zkontrolován odborníkem na daný předmět. Tento další krok v tréninku a kontrole zvyšuje schopnost AI odhalit abnormality a nemoci. Zvyšuje přesnost před doručením našim klientům.

Kardiologie
Naše anotace snímků zaměřená na kardiologii zpřesňuje diagnostiku AI. Přivádíme kardiologické odborníky, kteří označují složité obrázky související se srdcem a trénují naše modely umělé inteligence. Než odešleme data klientům, tito specialisté zkontrolují každý snímek, aby zajistili špičkovou přesnost. Tento proces umožňuje AI přesněji detekovat srdeční stavy.
Zubní lékařství
Naše služba anotací snímků ve stomatologii označuje zubní snímky pro vylepšení diagnostických nástrojů AI. Přesnou identifikací zubního kazu, problémů se zarovnáním zubů a dalších stavů chrupu umožňují naše malé a střední podniky AI zlepšit výsledky pacientů a podporovat zubní lékaře při přesném plánování léčby a včasné detekci.


















Lidé
Specializované a vyškolené týmy:
- Více než 30,000 XNUMX spolupracovníků pro vytváření, označování a kontrolu dat
- Tým pověřeného řízení projektů
- Zkušený tým vývoje produktů
- Tým získávání a přihlašování talentů

Proces
Nejvyšší účinnost procesu je zajištěna pomocí:
- Robustní 6stupňový proces sigma-gate
- Specializovaný tým 6 černých pásů Sigma - klíčoví vlastníci procesů a dodržování kvality
- Neustálé zlepšování a zpětná vazba

Plošina
Patentovaná platforma nabízí výhody:
- Webová platforma typu end-to-end
- Bezvadná kvalita
- Rychlejší TAT
- Bezproblémové doručení



