






Sbírka textů

Sbírka zvuku/řeči
Textová anotace
Anotace zvuku / řeči

Přepis textu

Přepis zvuku / řeči




Konverzační školení AI / Chatbot
Školení digitálních asistentů vyžaduje rozsáhlou sadu kvalitních dat z různých geografických oblastí, jazyků, dialektů, nastavení a formátů. Ve společnosti Shaip nabízíme školicí data pro modely AI s technologií Human-in-the-loop, kteří mají požadované znalosti, znalosti oboru a dobře si uvědomují specifické potřeby klienta.
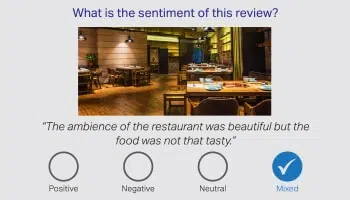
Sentiment / záměr
Analýza
Je správně řečeno, že slova sama o sobě nedokáží sdělit celý příběh a tíha leží na lidských anotátorech, aby interpretovali nejednoznačnost v lidském jazyce. Proto je nanejvýš důležité identifikovat Sentiment zákazníka na základě konverzace. Naši jazykoví experti z různých domén dokážou interpretovat nuance v recenzích produktů, finančních zprávách a sociálních médiích.

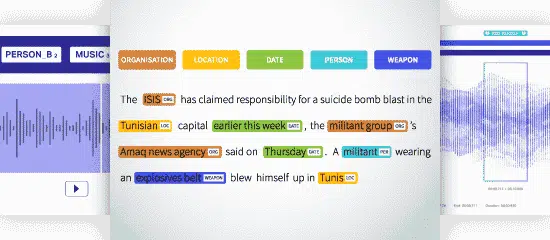
Rozpoznání pojmenované entity (NER)
Rozpoznávání pojmenovaných entit (NER) identifikuje, extrahuje a klasifikuje pojmenované entity v textu do předem definovaných kategorií. Text lze kategorizovat jako místo, název, organizaci, produkt, množství, hodnotu, procento atd. Pomocí NER můžete řešit otázky reálného světa, například o tom, které organizace byly v článku zmíněny atd.
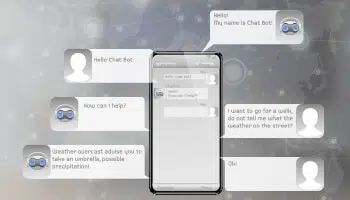
Automatizace klientských služeb
Robustní, dobře vyškolení virtuální chatboti nebo digitální asistenti způsobili revoluci ve způsobu, jakým zákazníci komunikují s prodejci, a významně zlepšili zákaznickou zkušenost.

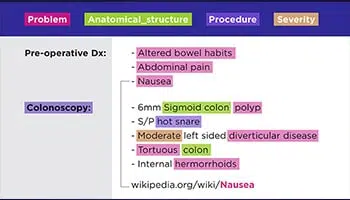
Přepis textu
Od ručně psaných receptů lékařů po poznámky z konferenčních hovorů mohou naši specialisté digitalizovat jakoukoli formu dat, tj. Archivované dokumenty, právní smlouvy, zdravotní záznamy pacientů atd.
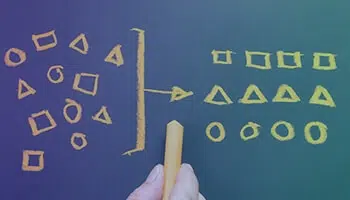
Kategorizace obsahu
Kategorizace, známá také jako klasifikace nebo označování, je proces třídění textu do organizovaných skupin a jeho označování na základě jeho zvláštností.

Analýza tématu
Analýza témat nebo označení témat je identifikace a extrakce významu z daného textu určením opakujících se uvažovaných témat / témat.

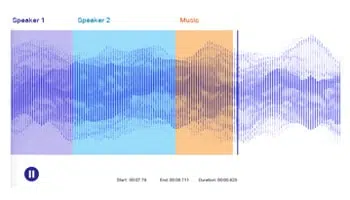
Přepis zvuku
Přepište řeč/podcast/seminář, zavolejte konverzaci do textu. Využijte lidi k přesné anotaci zvukových/řečových souborů a přesně trénujte modely NLP.

Klasifikace zvuku
Kategorizujte zvuky nebo promluvy ke klasifikaci řeči / zvuku na základě jazyka, dialektu, sémantiky, lexikonů atd.

Lidé
Specializované a vyškolené týmy:
- Více než 30,000 XNUMX spolupracovníků pro vytváření, označování a kontrolu dat
- Tým pověřeného řízení projektů
- Zkušený tým vývoje produktů
- Tým získávání a přihlašování talentů

Proces
Nejvyšší účinnost procesu je zajištěna pomocí:
- Robustní 6stupňový proces sigma-gate
- Specializovaný tým 6 černých pásů Sigma - klíčoví vlastníci procesů a dodržování kvality
- Neustálé zlepšování a zpětná vazba

Plošina
Patentovaná platforma nabízí výhody:
- Webová platforma typu end-to-end
- Bezvadná kvalita
- Rychlejší TAT
- Bezproblémové doručení


