

Co jsou velké jazykové modely?
Velké jazykové modely (LLM) jsou pokročilé systémy umělé inteligence (AI) navržené ke zpracování, porozumění a generování lidského textu. Jsou založeny na technikách hlubokého učení a trénovány na masivních souborech dat, které obvykle obsahují miliardy slov z různých zdrojů, jako jsou webové stránky, knihy a články. Toto rozsáhlé školení umožňuje LLM pochopit nuance jazyka, gramatiky, kontextu a dokonce i některé aspekty obecných znalostí.
Některé populární LLM, jako je OpenAI GPT-3, využívají typ neuronové sítě nazývaný transformátor, který jim umožňuje zvládat složité jazykové úlohy s pozoruhodnou odborností. Tyto modely mohou provádět širokou škálu úkolů, jako například:
- Odpovídání na otázky
- Shrnující text
- Překlady jazyků
- Generování obsahu
- Dokonce i zapojení do interaktivních konverzací s uživateli
Jak se LLM neustále vyvíjejí, mají velký potenciál pro vylepšování a automatizaci různých aplikací napříč odvětvími, od zákaznických služeb a tvorby obsahu až po vzdělávání a výzkum. Vyvolávají však také etické a společenské obavy, jako je neobjektivní chování nebo zneužívání, které je třeba řešit s technologickým pokrokem.

Oblíbené příklady velkých jazykových modelů
Zde je několik prominentních příkladů LLM široce používaných v různých průmyslových odvětvích:
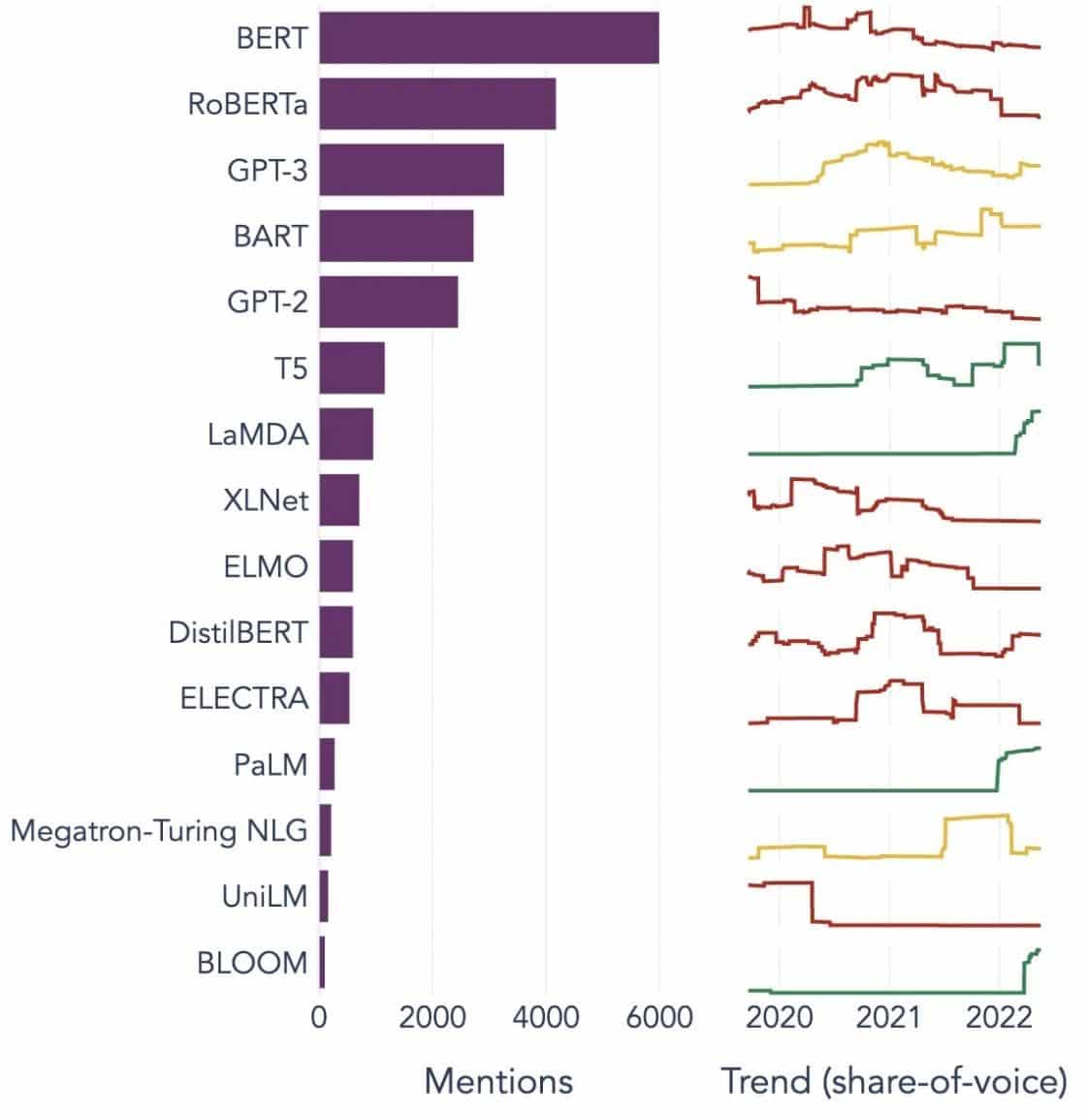
Zdroj obrázku: Směrem k datové vědě
Jak se školí modely LLM?
Školení velkých jazykových modelů (LLM) je docela výkon, který zahrnuje několik zásadních kroků. Zde je zjednodušený, krok za krokem shrnutí procesu:
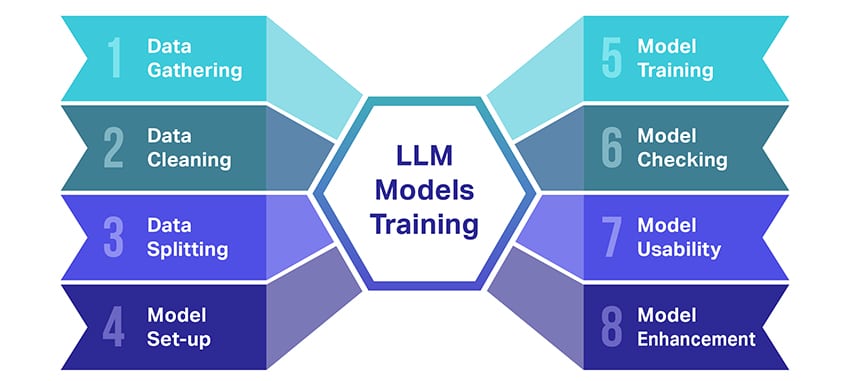
- Shromažďování textových dat: Školení LLM začíná sběrem obrovského množství textových dat. Tato data mohou pocházet z knih, webových stránek, článků nebo platforem sociálních médií. Cílem je zachytit bohatou rozmanitost lidského jazyka.
- Čištění dat: Nezpracovaná textová data se pak uklidí v procesu zvaném předběžné zpracování. To zahrnuje úkoly, jako je odstranění nežádoucích znaků, rozdělení textu na menší části nazývané tokeny a převedení všeho do formátu, se kterým může model pracovat.
- Rozdělení dat: Dále jsou čistá data rozdělena do dvou sad. Jedna sada, trénovací data, bude použita k trénování modelu. Druhá sada, ověřovací data, bude později použita k testování výkonu modelu.
- Nastavení modelu: Poté je definována struktura LLM, známá jako architektura. To zahrnuje výběr typu neuronové sítě a rozhodování o různých parametrech, jako je počet vrstev a skrytých jednotek v síti.
- Trénink modelky: Nyní začíná skutečný trénink. Model LLM se učí tak, že se dívá na trénovací data, vytváří předpovědi na základě toho, co se dosud naučil, a poté upravuje své interní parametry tak, aby se snížil rozdíl mezi jeho předpověďmi a skutečnými daty.
- Kontrola modelu: Učení modelu LLM se kontroluje pomocí ověřovacích dat. To pomáhá zjistit, jak dobře si model vede, a vyladit nastavení modelu pro lepší výkon.
- Použití modelu: Po zaškolení a vyhodnocení je model LLM připraven k použití. Nyní může být integrován do aplikací nebo systémů, kde bude generovat text na základě nových vstupů, které zadá.
- Vylepšení modelu: Konečně, vždy je co zlepšovat. Model LLM lze v průběhu času dále zdokonalovat pomocí aktualizovaných dat nebo úpravou nastavení na základě zpětné vazby a reálného použití.
Pamatujte, že tento proces vyžaduje značné výpočetní zdroje, jako jsou výkonné procesorové jednotky a velké úložiště, a také specializované znalosti v oblasti strojového učení. To je důvod, proč to obvykle provádějí specializované výzkumné organizace nebo společnosti s přístupem k potřebné infrastruktuře a odborným znalostem.
Spoléhá se LLM na řízené nebo nekontrolované učení?
Velké jazykové modely jsou obvykle trénovány pomocí metody zvané učení pod dohledem. Zjednodušeně to znamená, že se učí z příkladů, které jim ukazují správné odpovědi.
 Představte si, že učíte dítě slovíčka tím, že mu ukazujete obrázky. Ukážete jim obrázek kočky a řeknete „kočka“ a naučí se spojovat tento obrázek se slovem. Tak funguje učení pod dohledem. Model dostává spoustu textu („obrázky“) a odpovídajících výstupů („slova“) a učí se je spojovat.
Představte si, že učíte dítě slovíčka tím, že mu ukazujete obrázky. Ukážete jim obrázek kočky a řeknete „kočka“ a naučí se spojovat tento obrázek se slovem. Tak funguje učení pod dohledem. Model dostává spoustu textu („obrázky“) a odpovídajících výstupů („slova“) a učí se je spojovat.
Pokud tedy zadáte LLM větu, pokusí se předpovědět další slovo nebo frázi na základě toho, co se naučil z příkladů. Tímto způsobem se naučí generovat text, který dává smysl a zapadá do kontextu.
To znamená, že někdy LLM také používají trochu učení bez dozoru. Je to jako nechat dítě prozkoumat místnost plnou různých hraček a učit se o nich samo. Model se dívá na neoznačená data, vzorce učení a struktury, aniž by mu byly sděleny „správné“ odpovědi.
Učení pod dohledem využívá data, která byla označena vstupy a výstupy, na rozdíl od učení bez dozoru, které nepoužívá označená výstupní data.
Stručně řečeno, LLM se školí hlavně pomocí učení pod dohledem, ale mohou také používat učení bez dozoru ke zlepšení svých schopností, například pro průzkumnou analýzu a redukci rozměrů.
Jaký je objem dat (v GB) nezbytný pro trénování velkého jazykového modelu?
Svět možností pro rozpoznávání řečových dat a hlasové aplikace je obrovský a jsou využívány v několika průmyslových odvětvích pro nepřeberné množství aplikací.
Trénink velkého jazykového modelu není univerzální proces, zejména pokud jde o potřebná data. Záleží na spoustě věcí:
- Návrh modelu.
- Jakou práci musí dělat?
- Typ dat, která používáte.
- Jak dobře chcete, aby fungoval?
To znamená, že školení LLM obvykle vyžaduje obrovské množství textových dat. Ale o jak masivnosti mluvíme? No, přemýšlejte daleko za gigabajty (GB). Obvykle se díváme na terabajty (TB) nebo dokonce petabajty (PB) dat.
Zvažte GPT-3, jeden z největších LLM v okolí. Trénuje se na 570 GB textových dat. Menší LLM mohou potřebovat méně – možná 10–20 GB nebo dokonce 1 GB gigabajtů – ale stále je to hodně.

Nejde ale jen o velikost dat. Na kvalitě také záleží. Data musí být čistá a různorodá, aby pomohla modelu efektivně se učit. A nemůžete zapomenout na další klíčové kousky skládačky, jako je potřebný výpočetní výkon, algoritmy, které používáte pro trénink, a hardwarové nastavení, které máte. Všechny tyto faktory hrají velkou roli při školení LLM.
Vzestup velkých jazykových modelů: Proč na nich záleží
LLM již nejsou jen konceptem nebo experimentem. V našem digitálním prostředí hrají stále důležitější roli. Ale proč se to děje? Proč jsou tyto LLM tak důležité? Pojďme se ponořit do některých klíčových faktorů.
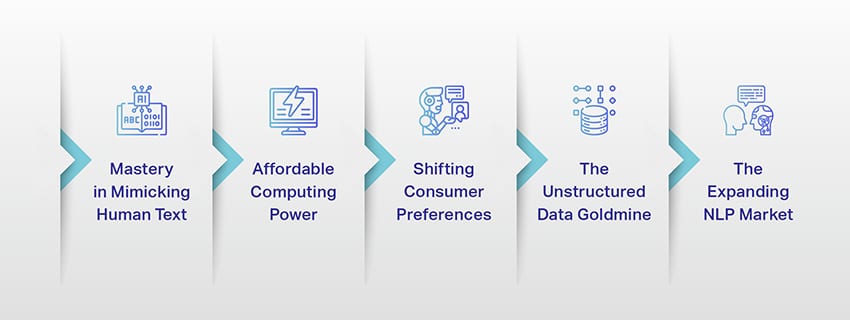
Mistrovství v napodobování lidského textu
LLM změnily způsob, jakým zpracováváme jazykové úkoly. Tyto modely jsou vytvořeny pomocí robustních algoritmů strojového učení a jsou vybaveny schopností porozumět nuancím lidského jazyka, včetně kontextu, emocí a dokonce i sarkasmu, do určité míry. Tato schopnost napodobovat lidský jazyk není pouhou novinkou, má významné důsledky.
Pokročilé schopnosti generování textu LLM mohou vylepšit vše od tvorby obsahu až po interakce se zákaznickým servisem.
Představte si, že můžete položit digitálnímu asistentovi komplexní otázku a dostat odpověď, která nejen dává smysl, ale je také koherentní, relevantní a podaná v konverzačním tónu. To LLM umožňují. Podporují intuitivnější a poutavější interakci mezi člověkem a strojem, obohacují uživatelské zkušenosti a demokratizují přístup k informacím.
Cenově dostupný výpočetní výkon
Vzestup LLM by nebyl možný bez paralelního vývoje v oblasti výpočetní techniky. Přesněji řečeno, demokratizace výpočetních zdrojů sehrála významnou roli ve vývoji a přijetí LLM.
Cloudové platformy nabízejí bezprecedentní přístup k vysoce výkonným výpočetním zdrojům. Tímto způsobem mohou i malé organizace a nezávislí výzkumníci trénovat sofistikované modely strojového učení.
Vylepšení procesorových jednotek (jako jsou GPU a TPU) v kombinaci s nárůstem distribuovaného počítání navíc umožnilo trénovat modely s miliardami parametrů. Tato zvýšená dostupnost výpočetního výkonu umožňuje růst a úspěch LLM, což vede k většímu množství inovací a aplikací v této oblasti.
Změna spotřebitelských preferencí
Dnešní spotřebitelé nechtějí jen odpovědi; chtějí poutavé a příbuzné interakce. S tím, jak stále více lidí vyrůstá pomocí digitální technologie, je evidentní, že potřeba technologie, která působí přirozeněji a lidsky, roste. LLM nabízejí bezkonkurenční příležitost, jak tato očekávání splnit. Generováním lidského textu mohou tyto modely vytvářet poutavé a dynamické digitální zážitky, které mohou zvýšit spokojenost a loajalitu uživatelů. Ať už jde o chatboty s umělou inteligencí poskytující zákaznický servis nebo hlasové asistenty poskytující aktualizace novinek, LLM zahajují éru umělé inteligence, která nám lépe rozumí.
Zlatý důl nestrukturovaných dat
Nestrukturovaná data, jako jsou e-maily, příspěvky na sociálních sítích a recenze zákazníků, jsou pokladnicí vhledů. Odhaduje se, že konec 80% podnikových dat je nestrukturovaná a roste rychlostí 55% za rok. Tato data jsou pro podniky zlatým dolem, pokud jsou správně využívána.
Zde vstupují do hry LLM se schopností zpracovávat a dávat smysl takovým datům ve velkém měřítku. Zvládnou úkoly, jako je analýza sentimentu, klasifikace textu, extrakce informací a další, a tím poskytují cenné poznatky.
Ať už jde o identifikaci trendů z příspěvků na sociálních sítích nebo měření sentimentu zákazníků z recenzí, LLM pomáhají podnikům orientovat se ve velkém množství nestrukturovaných dat a činit rozhodnutí na základě dat.
Rozšiřující se trh NLP
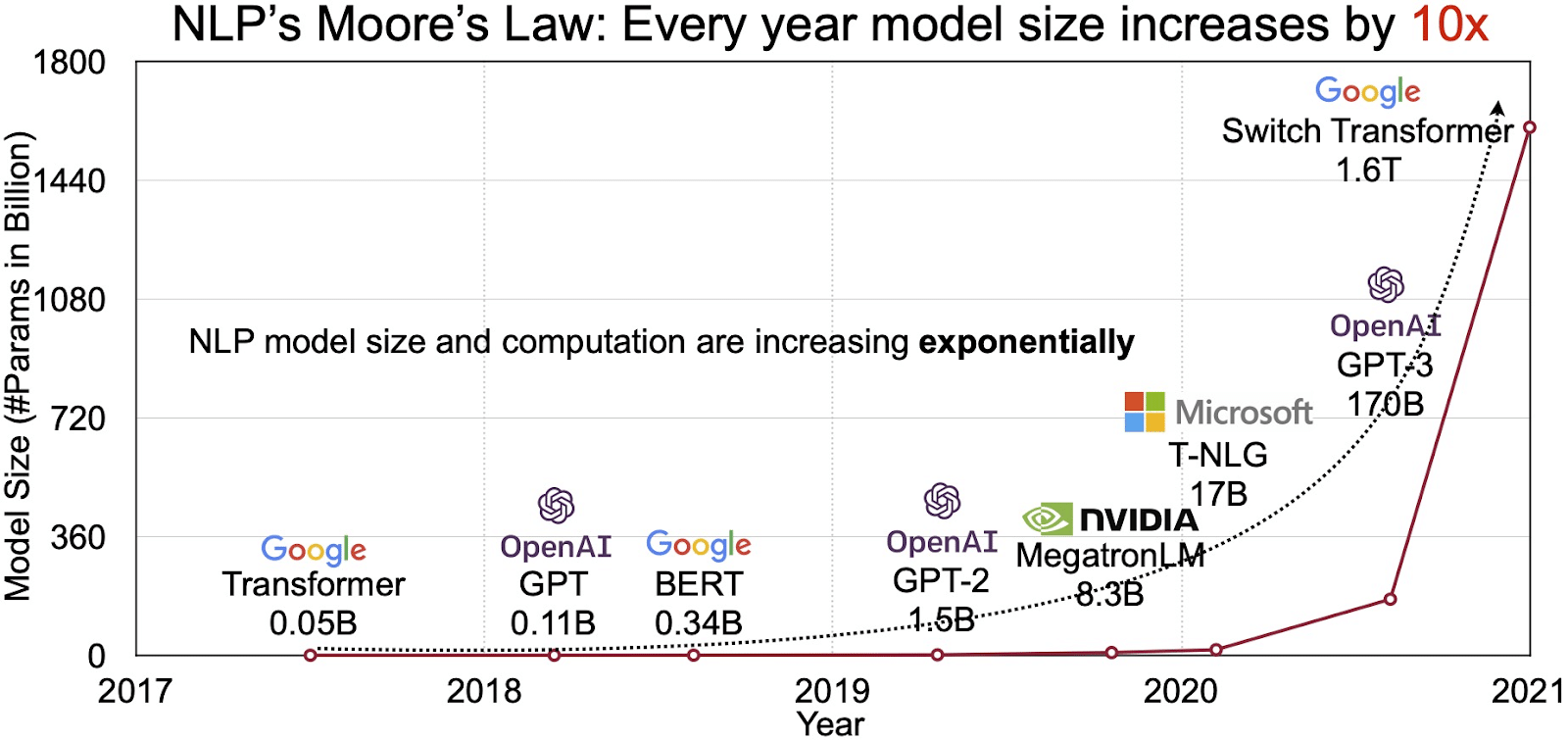
Potenciál LLM se odráží v rychle rostoucím trhu pro zpracování přirozeného jazyka (NLP). Analytici předpokládají, že trh NLP bude expandovat 11 miliard USD v roce 2020 na více než 35 miliard USD v roce 2026. Ale není to jen velikost trhu, která se rozšiřuje. Rostou i samotné modely, a to jak fyzickými rozměry, tak počtem parametrů, které zvládají. Vývoj LLM v průběhu let, jak je vidět na obrázku níže (zdroj obrázku: odkaz), podtrhuje jejich rostoucí složitost a kapacitu.
Populární případy použití velkých jazykových modelů
Zde jsou některé z hlavních a nejrozšířenějších případů použití LLM:
- Generování textu v přirozeném jazyce: Velké jazykové modely (LLM) kombinují sílu umělé inteligence a výpočetní lingvistiky k autonomní tvorbě textů v přirozeném jazyce. Mohou uspokojit různé potřeby uživatelů, jako je psaní článků, tvorba písní nebo konverzace s uživateli.
- Překlad přes stroje: LLM lze efektivně využít k překladu textu mezi jakoukoli dvojicí jazyků. Tyto modely využívají algoritmy hlubokého učení, jako jsou rekurentní neuronové sítě, k pochopení jazykové struktury jak zdrojového, tak cílového jazyka, a tím usnadňují překlad zdrojového textu do požadovaného jazyka.
- Vytváření původního obsahu: LLM otevřely možnosti pro stroje generovat soudržný a logický obsah. Tento obsah lze použít k vytváření blogových příspěvků, článků a dalších typů obsahu. Modely využívají své hluboké zkušenosti s hlubokým učením a formátují a strukturují obsah novým a uživatelsky přívětivým způsobem.
- Analýza pocitů: Jednou ze zajímavých aplikací velkých jazykových modelů je analýza sentimentu. V tomto je model trénován k rozpoznání a kategorizaci emočních stavů a sentimentů přítomných v anotovaném textu. Software dokáže identifikovat emoce, jako je pozitivita, negativita, neutralita a další složité pocity. To může poskytnout cenné informace o zpětné vazbě zákazníků a názorech na různé produkty a služby.
- Pochopení, shrnutí a klasifikace textu: LLM vytvářejí životaschopnou strukturu pro software AI pro interpretaci textu a jeho kontextu. Tím, že dávají modelu pokyn, aby porozuměl a prozkoumal obrovské množství dat, umožňují LLM modelům AI porozumět, shrnout a dokonce kategorizovat text v různých formách a vzorech.
- Odpovědi na otázky: Velké jazykové modely vybavují systémy odpovědí na otázky (QA) schopností přesně vnímat a reagovat na dotaz uživatele v přirozeném jazyce. Oblíbené příklady tohoto případu použití zahrnují ChatGPT a BERT, které zkoumají kontext dotazu a probírají rozsáhlou sbírku textů, aby poskytly relevantní odpovědi na otázky uživatelů.

Part-of-Speech (POS) značkování
Slova ve větách jsou označena svou gramatickou funkcí, jako jsou slovesa, podstatná jména, přídavná jména atd. Tento proces pomáhá modelu pochopit gramatiku a vazby mezi slovy.

Rozpoznání pojmenované entity (NER)
Pojmenované entity, jako jsou organizace, místa a lidé ve větě, jsou označeny. Toto cvičení pomáhá modelu při interpretaci sémantických významů slov a frází a poskytuje přesnější odpovědi.

Analýza sentimentu
Textovým datům jsou přiřazeny sentimentální štítky jako pozitivní, neutrální nebo negativní, což modelu pomáhá pochopit emocionální podtext vět. Je zvláště užitečné při odpovídání na dotazy týkající se emocí a názorů.
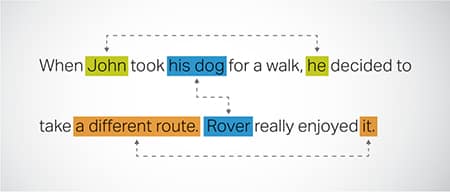
Koreference rozlišení
Identifikace a řešení případů, kdy se v různých částech textu odkazuje na stejnou entitu. Tento krok pomáhá modelu porozumět kontextu věty, což vede ke koherentním odpovědím.
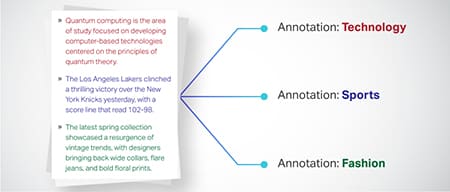
Klasifikace textu
Textová data jsou kategorizována do předem definovaných skupin, jako jsou recenze produktů nebo novinové články. To pomáhá modelu rozlišit žánr nebo téma textu a generovat relevantnější odpovědi.
Shaipova nabídka
Saip nabízí širokou škálu služeb, které organizacím pomáhají spravovat, analyzovat a co nejlépe využívat jejich data.
Data Web-Scraping
Jednou z klíčových služeb nabízených společností Shaip je seškrabování dat. To zahrnuje extrakci dat z adres URL specifických pro doménu. Využitím automatizovaných nástrojů a technik může Shaip rychle a efektivně sbírat velké objemy dat z různých webových stránek, produktových manuálů, technické dokumentace, online fór, online recenzí, dat zákaznických služeb, průmyslových regulačních dokumentů atd. Tento proces může být pro podniky neocenitelný, když shromažďování relevantních a konkrétních údajů z mnoha zdrojů.

Strojový překlad
Vyvíjejte modely pomocí rozsáhlých vícejazyčných datových sad spárovaných s odpovídajícími přepisy pro překlad textu do různých jazyků. Tento proces pomáhá odstraňovat jazykové překážky a podporuje dostupnost informací.
Extrakce a tvorba taxonomie
Shaip může pomoci s extrakcí a tvorbou taxonomie. To zahrnuje klasifikaci a kategorizaci dat do strukturovaného formátu, který odráží vztahy mezi různými datovými body. To může být užitečné zejména pro podniky při organizování dat, díky nimž jsou přístupnější a snadněji analyzovatelné. Například v e-shopu mohou být produktová data kategorizována podle typu produktu, značky, ceny atd., což zákazníkům usnadňuje orientaci v katalogu produktů.
Sběr dat
Naše služby sběru dat poskytují kritická reálná nebo syntetická data nezbytná pro trénování generativních algoritmů umělé inteligence a zlepšování přesnosti a efektivity vašich modelů. Data jsou nezaujatá, eticky a zodpovědně získávána, přičemž je třeba mít na paměti soukromí a bezpečnost dat.

Otázka a odpověď
Odpovídání na otázky (QA) je podpolí zpracování přirozeného jazyka zaměřené na automatické odpovídání na otázky v lidské řeči. Systémy QA jsou trénovány na rozsáhlém textu a kódu, což jim umožňuje zpracovávat různé typy otázek, včetně faktických, definičních a názorových. Znalost domény je zásadní pro vývoj modelů QA přizpůsobených konkrétním oblastem, jako je zákaznická podpora, zdravotní péče nebo dodavatelský řetězec. Nicméně, generativní QA přístupy umožňují modelům generovat text bez znalosti domény, spoléhat se pouze na kontext.
Náš tým specialistů může pečlivě prostudovat komplexní dokumenty nebo manuály, aby vytvořil páry otázek a odpovědí, což podnikům usnadní vytvoření generativní umělé inteligence. Tento přístup může efektivně řešit dotazy uživatelů dolováním relevantních informací z rozsáhlého korpusu. Naši certifikovaní odborníci zajišťují produkci vysoce kvalitních párů otázek a odpovědí, které pokrývají různá témata a oblasti.

Shrnutí textu
Naši specialisté jsou schopni vytvořit komplexní konverzace nebo dlouhé dialogy a poskytnout stručné a bystré shrnutí z rozsáhlých textových dat.

Generování textu
Trénujte modely pomocí široké datové sady textu v různých stylech, jako jsou zpravodajské články, beletrie a poezie. Tyto modely pak mohou generovat různé typy obsahu, včetně novinových článků, příspěvků na blogu nebo příspěvků na sociálních sítích, což nabízí nákladově efektivní a časově úsporné řešení pro tvorbu obsahu.
Rozpoznávání řeči
Vyvíjet modely schopné porozumět mluvené řeči pro různé aplikace. To zahrnuje hlasově aktivované asistenty, diktovací software a překladatelské nástroje v reálném čase. Proces zahrnuje využití komplexního datového souboru složeného ze zvukových nahrávek mluveného jazyka, spárovaných s jejich odpovídajícími přepisy.

Doporučení produktu
Vyvíjejte modely s využitím rozsáhlých datových souborů historie nákupů zákazníků, včetně štítků, které poukazují na produkty, které zákazníci inklinují ke koupi. Cílem je poskytovat zákazníkům přesné návrhy, a tím zvýšit prodej a zvýšit spokojenost zákazníků.
Titulky obrázků
Udělejte revoluci ve svém procesu interpretace obrázků s naší nejmodernější službou Image Captioning řízenou umělou inteligencí. Vkládáme do obrázků vitalitu tím, že vytváříme přesné a kontextově smysluplné popisy. To otevírá cestu pro inovativní zapojení a možnosti interakce s vaším vizuálním obsahem pro vaše publikum.

Školení služeb převodu textu na řeč
Poskytujeme rozsáhlou datovou sadu sestávající ze zvukových nahrávek lidské řeči, ideální pro trénování modelů umělé inteligence. Tyto modely dokážou generovat přirozené a poutavé hlasy pro vaše aplikace, a tak poskytují vašim uživatelům charakteristický a pohlcující zvukový zážitek.



