
Úvod
Tato příručka bude nesmírně užitečná pro ty kupující a osoby s rozhodovací pravomocí, kteří začínají obracet své myšlenky k základům získávání dat a implementaci dat jak pro neuronové sítě, tak pro jiné typy operací AI a ML.

Tento článek je zcela věnován objasnění toho, jaký je tento proces, proč je nevyhnutelný, zásadní
faktory, které by společnosti měly vzít v úvahu při přístupu k nástrojům pro anotaci dat a dalším. Pokud tedy vlastníte firmu, připravte se na osvícení, protože vás tento průvodce provede vším, co potřebujete vědět o anotaci dat.
Začněme.
Pro ty z vás, kteří procházejí tento článek, zde je několik rychlých záznamů, které najdete v příručce:
- Pochopte, co je to anotace dat
- Znát různé typy procesů anotace dat
- Seznamte se s výhodami implementace procesu anotace dat
- Získejte jasno v tom, zda byste měli jít na interní označování dat, nebo je nechat outsourcovat
- Informace o výběru správné anotace dat
Co je strojové učení?
 Mluvili jsme o tom, jak anotace dat popř označení dat podporuje strojové učení a že se skládá ze značkování nebo identifikace součástí. Ale pokud jde o hluboké učení a samotné strojové učení: základním předpokladem strojového učení je, že počítačové systémy a programy mohou zlepšit své výstupy způsoby, které se podobají lidským kognitivním procesům, bez přímé lidské pomoci nebo zásahu, aby nám poskytly vhled. Jinými slovy, stávají se z nich samoučící se stroje, které se podobně jako člověk zdokonalují ve své práci s větší praxí. Tato „praxe“ se získává z analýzy a interpretace více (a lepších) tréninkových dat.
Mluvili jsme o tom, jak anotace dat popř označení dat podporuje strojové učení a že se skládá ze značkování nebo identifikace součástí. Ale pokud jde o hluboké učení a samotné strojové učení: základním předpokladem strojového učení je, že počítačové systémy a programy mohou zlepšit své výstupy způsoby, které se podobají lidským kognitivním procesům, bez přímé lidské pomoci nebo zásahu, aby nám poskytly vhled. Jinými slovy, stávají se z nich samoučící se stroje, které se podobně jako člověk zdokonalují ve své práci s větší praxí. Tato „praxe“ se získává z analýzy a interpretace více (a lepších) tréninkových dat.
Co je datová anotace?
Anotace dat je proces přiřazování, označování nebo označování dat, který pomáhá algoritmům strojového učení pochopit a klasifikovat informace, které zpracovávají. Tento proces je nezbytný pro trénování modelů umělé inteligence, které jim umožňují přesně porozumět různým typům dat, jako jsou obrázky, zvukové soubory, videozáznamy nebo text.
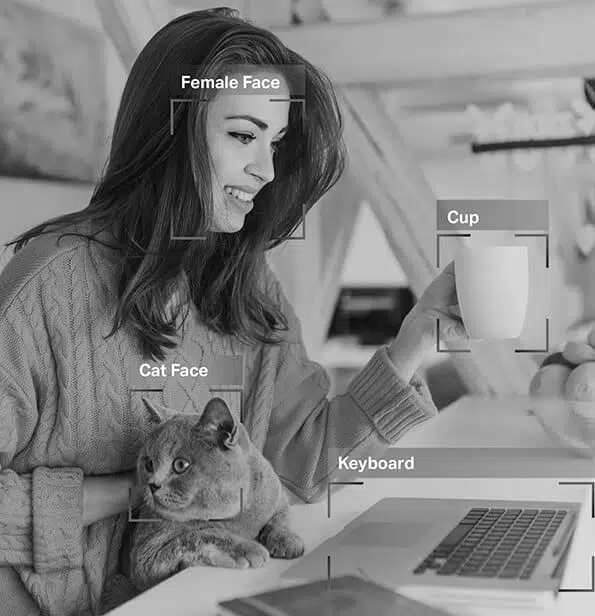
Představte si auto s vlastním řízením, které se při přesných rozhodnutích o řízení spoléhá na data z počítačového vidění, zpracování přirozeného jazyka (NLP) a senzory. Aby model umělé inteligence auta mohl rozlišit překážky, jako jsou jiná vozidla, chodci, zvířata nebo zátarasy, musí být přijímaná data označena nebo opatřena poznámkami.
Při učení pod dohledem je anotace dat obzvláště důležitá, protože čím více označených dat je do modelu přiváděno, tím rychleji se model naučí fungovat autonomně. Anotovaná data umožňují nasazení modelů umělé inteligence v různých aplikacích, jako jsou chatboti, rozpoznávání řeči a automatizace, což vede k optimálnímu výkonu a spolehlivým výsledkům.
Co je nástroj pro označování/anotaci dat?
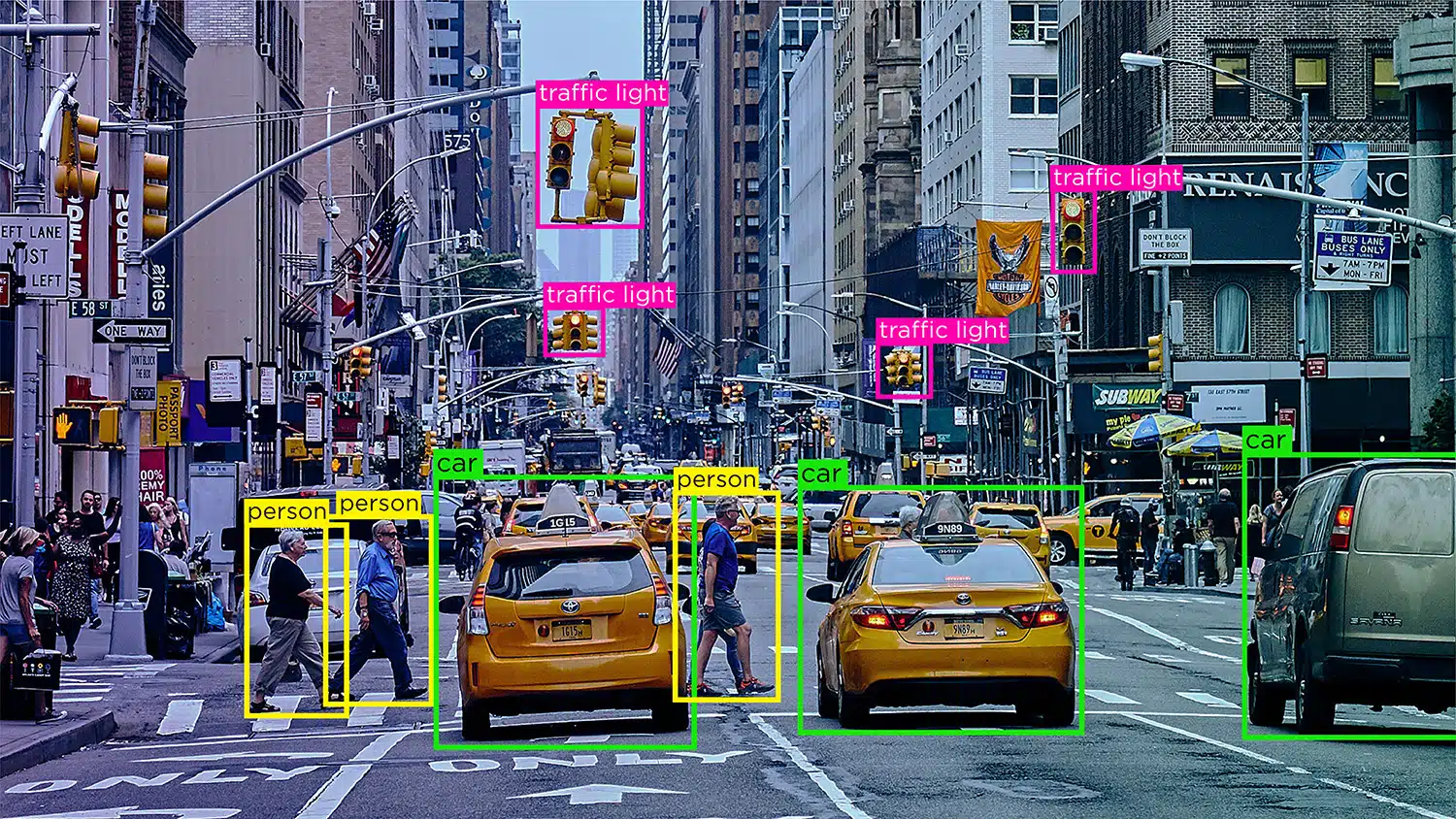
 Jednoduše řečeno, je to platforma nebo portál, který umožňuje odborníkům a odborníkům anotovat, označovat nebo označovat datové sady všech typů. Je to most nebo médium mezi nezpracovanými daty a výsledky, které by vaše moduly strojového učení nakonec vychrlily.
Jednoduše řečeno, je to platforma nebo portál, který umožňuje odborníkům a odborníkům anotovat, označovat nebo označovat datové sady všech typů. Je to most nebo médium mezi nezpracovanými daty a výsledky, které by vaše moduly strojového učení nakonec vychrlily.
Nástroj pro označování dat je on-prem nebo cloudové řešení, které anotuje vysoce kvalitní školicí data pro modely strojového učení. I když mnoho společností spoléhá na externí dodavatele, který provádí složité anotace, některé organizace stále mají vlastní nástroje, které jsou buď vytvořeny na míru, nebo jsou založeny na freeware nebo opensource nástrojích dostupných na trhu. Tyto nástroje jsou obvykle navrženy pro zpracování konkrétních datových typů, tj. Obrázků, videa, textu, zvuku atd. Nástroje nabízejí funkce nebo možnosti, jako jsou ohraničovací rámečky nebo polygony pro anotátory dat pro označování obrázků. Mohou jen vybrat možnost a provádět své konkrétní úkoly.
Anotace obrázku

Z datových sad, na které byli vyškoleni, dokážou okamžitě a přesně odlišit vaše oči od nosu a vaše obočí od řas. Proto filtry, které použijete, perfektně sedí bez ohledu na tvar vašeho obličeje, jak blízko jste k fotoaparátu a další.
Takže, jak nyní víte, anotace obrázku je zásadní v modulech, které zahrnují rozpoznávání obličeje, počítačové vidění, robotické vidění a další. Když odborníci na umělou inteligenci takové modely školí, přidávají k obrázkům jako atributy titulky, identifikátory a klíčová slova. Algoritmy pak identifikují a chápou z těchto parametrů a učí se samostatně.
Klasifikace obrázku – Klasifikace obrázků zahrnuje přiřazení předdefinovaných kategorií nebo štítků obrázkům na základě jejich obsahu. Tento typ anotací se používá k trénování modelů umělé inteligence, aby automaticky rozpoznávaly a kategorizovaly obrázky.
Rozpoznávání/detekce objektů – Rozpoznávání objektů nebo detekce objektů je proces identifikace a označení konkrétních objektů v rámci obrázku. Tento typ anotací se používá k trénování modelů umělé inteligence k vyhledání a rozpoznání objektů na obrázcích nebo videích v reálném světě.
Segmentace – Segmentace obrazu zahrnuje rozdělení obrazu na více segmentů nebo oblastí, z nichž každý odpovídá konkrétnímu objektu nebo oblasti zájmu. Tento typ anotace se používá k trénování modelů AI k analýze obrázků na úrovni pixelů, což umožňuje přesnější rozpoznání objektů a pochopení scény.
Zvuková anotace
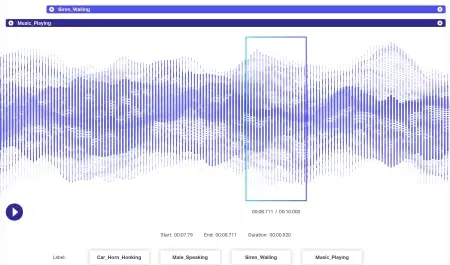
K audio datům je připojena ještě větší dynamika než obrazová data. Se zvukovým souborem je spojeno několik faktorů, mimo jiné - jazyk, demografické údaje mluvčích, dialekty, nálada, záměr, emoce, chování. Aby byly algoritmy efektivní při zpracování, měly by být všechny tyto parametry identifikovány a označeny technikami, jako je časové razítko, zvukové označení a další. Kromě pouze verbálních narážek mohou být systémy, které komplexně rozumějí, anotovány neverbální instance, jako je ticho, dechy, dokonce i hluk pozadí.
Video anotace

Zatímco je obraz nehybný, video je kompilací obrazů, které vytvářejí efekt pohybujících se objektů. Nyní se každý obrázek v této kompilaci nazývá rám. Pokud jde o anotaci videa, proces zahrnuje přidání klíčových bodů, polygonů nebo ohraničujících rámečků pro anotaci různých objektů v poli v každém snímku.
Když jsou tyto snímky spojeny dohromady, modely AI v akci se mohou naučit pohyb, chování, vzory a další. Je to pouze skrz anotace videa že koncepty jako lokalizace, rozostření pohybu a sledování objektů by mohly být implementovány v systémech.
Textová anotace

Dnes je většina podniků závislá na textových datech pro jedinečný přehled a informace. Nyní by text mohl být cokoli, od zpětné vazby zákazníků k aplikaci až po zmínku o sociálních médiích. A na rozdíl od obrázků a videí, které většinou vyjadřují přímočaré úmysly, text přichází se spoustou sémantiky.
Jako lidé jsme naladěni na porozumění kontextu fráze, významu každého slova, věty nebo fráze, vztahujeme je k určité situaci nebo konverzaci a poté si uvědomíme holistický význam, který je za výrazem. Na druhé straně to stroje nemohou dělat na přesných úrovních. Pojmy jako sarkasmus, humor a další abstraktní prvky pro ně nejsou známé, a proto je značení textových dat obtížnější. Proto má textová anotace některé rafinovanější fáze, například následující:
Sémantická anotace - objekty, produkty a služby jsou relevantnější díky vhodným tagováním klíčových slov a identifikačním parametrům. Chatboty jsou také vyrobeny tak, aby napodobovaly lidské konverzace tímto způsobem.
Anotace záměru - úmysl uživatele a jazyk, který používají, jsou označeny tak, aby mu stroje rozuměly. Díky tomu mohou modely odlišit požadavek od příkazu nebo doporučení od rezervace atd.
Sentimentová anotace – Anotace sentimentu zahrnuje označení textových dat sentimentem, který vyjadřuje, jako je pozitivní, negativní nebo neutrální. Tento typ anotace se běžně používá v analýze sentimentu, kde jsou modely umělé inteligence trénovány tak, aby porozuměly a vyhodnotily emoce vyjádřené v textu.

Anotace entity - kde jsou označeny nestrukturované věty, aby byly smysluplnější a přivedly je do formátu, kterému budou stroje rozumět. K tomu je třeba zahrnout dva aspekty - uznání pojmenované entity a propojení entit. Rozpoznání pojmenované entity je, když jsou označena a identifikována jména míst, lidí, událostí, organizací a dalších, a propojení entit je, když jsou tyto značky spojeny s větami, frázemi, fakty nebo názory, které je následují. Společně tyto dva procesy vytvářejí vztah mezi souvisejícími texty a tvrzením, které je obklopuje.
Kategorizace textu – Věty nebo odstavce lze označit a klasifikovat na základě zastřešujících témat, trendů, předmětů, názorů, kategorií (sport, zábava a podobně) a dalších parametrů.
Klíčové kroky v procesu označování dat a anotace dat
Proces anotace dat zahrnuje řadu dobře definovaných kroků k zajištění vysoce kvalitního a přesného označování dat pro aplikace strojového učení. Tyto kroky pokrývají všechny aspekty procesu, od sběru dat až po export anotovaných dat pro další použití.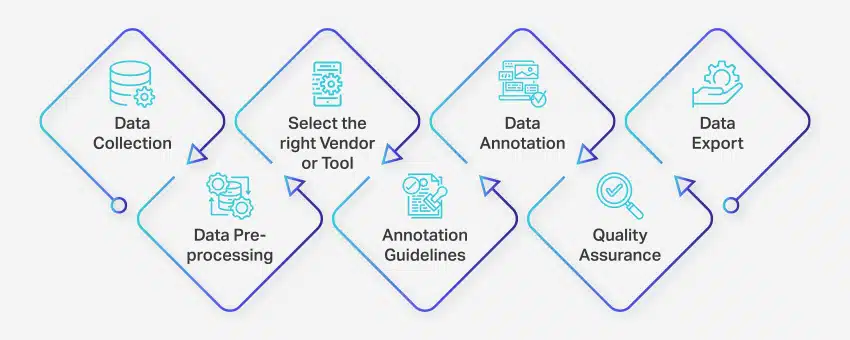
Takto probíhá anotace dat:
- Sběr dat: Prvním krokem v procesu anotace dat je shromáždit všechna relevantní data, jako jsou obrázky, videa, zvukové nahrávky nebo textová data, na centralizovaném místě.
- Předzpracování dat: Standardizujte a vylepšujte shromážděná data vyrovnáváním obrázků, formátováním textu nebo přepisem video obsahu. Předzpracování zajišťuje, že data jsou připravena k anotaci.
- Vyberte správného dodavatele nebo nástroj: Vyberte si vhodný nástroj pro anotaci dat nebo dodavatele na základě požadavků vašeho projektu. Možnosti zahrnují platformy jako Nanonets pro anotaci dat, V7 pro anotaci obrázků, Appen pro anotaci videa a Nanonets pro anotaci dokumentu.
- Pokyny pro anotaci: Stanovte jasné pokyny pro anotátory nebo anotační nástroje, abyste zajistili konzistenci a přesnost v celém procesu.
- Anotace: Označte a označte data pomocí lidských anotátorů nebo softwaru pro anotaci dat podle zavedených pokynů.
- Zajištění kvality (QA): Zkontrolujte anotovaná data, abyste zajistili přesnost a konzistenci. V případě potřeby použijte více slepých anotací, abyste ověřili kvalitu výsledků.
- Export dat: Po dokončení anotace dat exportujte data v požadovaném formátu. Platformy jako Nanonets umožňují bezproblémový export dat do různých podnikových softwarových aplikací.
Celý proces anotace dat se může pohybovat od několika dnů do několika týdnů, v závislosti na velikosti projektu, složitosti a dostupných zdrojích.
Funkce pro nástroje pro anotaci dat a označení dat
Nástroje pro anotaci dat jsou rozhodujícími faktory, které by mohly způsobit nebo rozbít váš projekt AI. Pokud jde o přesné výstupy a výsledky, na kvalitě samotných datových sad nezáleží. Ve skutečnosti nástroje pro anotaci dat, které používáte k trénování vašich modulů AI, nesmírně ovlivňují vaše výstupy.
Proto je důležité vybrat a používat nejfunkčnější a nejvhodnější nástroj pro označování dat, který odpovídá potřebám vaší firmy nebo projektu. Co je to ale vůbec nástroj pro anotaci dat? Jakému účelu slouží? Existují nějaké typy? Pojďme to zjistit.
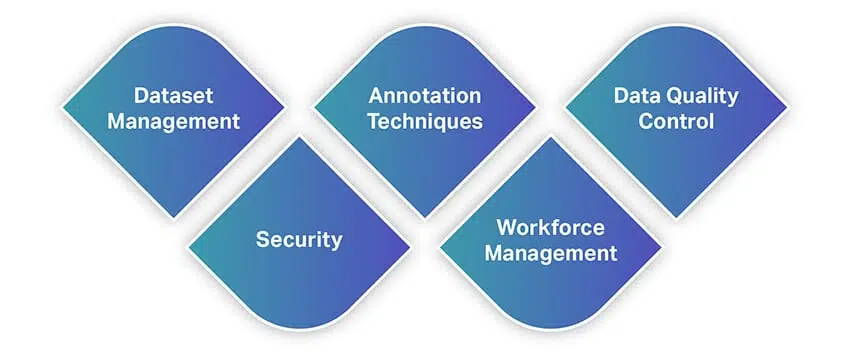
Podobně jako jiné nástroje nabízejí nástroje pro anotaci dat širokou škálu funkcí a možností. Abyste měli rychlou představu o funkcích, zde je seznam některých nejzákladnějších funkcí, které byste měli při výběru nástroje pro anotaci dat hledat.
Správa datových sad
Nástroj pro anotaci dat, který hodláte použít, musí podporovat datové sady, které máte v ruce, a nechat je importovat do softwaru pro označování. Správa vašich datových sad je tedy nabídkou nástrojů primárních funkcí. Současná řešení nabízejí funkce, které vám umožní bezproblémový import velkých objemů dat a současně vám umožní organizovat vaše datové sady pomocí akcí, jako je třídění, filtrování, klonování, sloučení a další.
Jakmile je zadáno vaše datové sady, další je exportuje jako použitelné soubory. Nástroj, který používáte, by vám měl umožnit uložit vaše datové sady ve formátu, který zadáte, abyste je mohli přenést do svých ML módů.
Techniky anotací
K tomu je nástroj anotace dat vytvořen nebo určen. Solidní nástroj by vám měl nabídnout řadu anotačních technik pro datové sady všech typů. To je, pokud nevyvíjíte vlastní řešení pro vaše potřeby. Váš nástroj by vám měl umožnit anotaci videa nebo obrázků z počítačového vidění, zvuku nebo textu z NLP a přepisů a další. Při dalším upřesnění by měly existovat možnosti použít ohraničující rámečky, sémantickou segmentaci, kvádry, interpolaci, analýzu sentimentu, části řeči, řešení koreference a další.
Pro nezasvěcené existují také nástroje pro anotaci dat poháněné umělou inteligencí. Dodávají se s moduly AI, které se samostatně učí z pracovních vzorců anotátora a automaticky anotují obrázky nebo text. Takový
Moduly lze použít k poskytování neuvěřitelné pomoci anotátorům, optimalizaci anotací a dokonce implementaci kontroly kvality.
Kontrola kvality dat
Když mluvíme o kontrolách kvality, existuje několik nástrojů pro anotaci dat s integrovanými moduly kontroly kvality. Ty umožňují anotátorům lepší spolupráci se členy jejich týmu a pomáhají optimalizovat pracovní postupy. Díky této funkci mohou anotátoři v reálném čase označovat a sledovat komentáře nebo zpětnou vazbu, sledovat identity lidí, kteří provádějí změny v souborech, obnovit předchozí verze, rozhodnout se pro konsenzus označování a další.
Bezpečnost
Protože pracujete s daty, mělo by mít zabezpečení nejvyšší prioritu. Možná pracujete na důvěrných datech, jako jsou osobní údaje nebo duševní vlastnictví. Váš nástroj tedy musí poskytovat vzduchotěsné zabezpečení, pokud jde o to, kde jsou data uložena a jak jsou sdílena. Musí poskytovat nástroje, které omezují přístup členům týmu, zabraňují neoprávněnému stahování a další.
Kromě toho musí být dodržovány a dodržovány bezpečnostní standardy a protokoly.
Řízení pracovních sil
Nástroj pro anotaci dat je také platformou pro projektový management, kde lze členům týmu přiřazovat úkoly, může docházet ke spolupráci, je možné provádět recenze a další. Proto by váš nástroj měl zapadnout do vašeho pracovního toku a procesu pro optimalizovanou produktivitu.
Kromě toho musí mít nástroj také minimální křivku učení, protože samotný proces anotace dat je časově náročný. Neslouží žádnému účelu, trávit příliš mnoho času prostým učením nástroje. Mělo by tedy být intuitivní a bezproblémové, aby kdokoli rychle začal.
Jaké jsou výhody anotace dat?
Anotace dat je zásadní pro optimalizaci systémů strojového učení a poskytování lepších uživatelských zkušeností. Zde jsou některé klíčové výhody anotace dat:
- Zlepšená efektivita tréninku: Označování dat pomáhá lépe trénovat modely strojového učení, zvyšuje celkovou efektivitu a poskytuje přesnější výsledky.
- Zvýšená přesnost: Přesně anotovaná data zajišťují, že se algoritmy mohou efektivně přizpůsobovat a učit se, což vede k vyšší úrovni přesnosti v budoucích úkolech.
- Snížený lidský zásah: Pokročilé nástroje pro anotaci dat výrazně snižují potřebu ručního zásahu, zefektivňují procesy a snižují související náklady.
Anotace dat tedy přispívá k efektivnějším a přesnějším systémům strojového učení a zároveň minimalizuje náklady a manuální úsilí, které je tradičně nutné k trénování modelů umělé inteligence.
Vytvořit nebo nevybudovat nástroj pro anotaci dat
Jedním z kritických a zastřešujících problémů, které se mohou objevit během projektu anotace dat nebo označování dat, je volba budovat nebo kupovat funkce pro tyto procesy. To může nastat několikrát v různých fázích projektu nebo v souvislosti s různými segmenty programu. Při výběru, zda budovat systém interně nebo se spoléhat na dodavatele, je vždy kompromis.

Jak nyní pravděpodobně víte, anotace dat je složitý proces. Zároveň je to také subjektivní proces. To znamená, že neexistuje jediná odpověď na otázku, zda byste si měli koupit nebo vytvořit nástroj pro anotaci dat. Je třeba vzít v úvahu mnoho faktorů a musíte si položit několik otázek, abyste pochopili své požadavky a uvědomili si, zda skutečně potřebujete koupit nebo postavit.
Abychom to zjednodušili, je zde několik faktorů, které byste měli zvážit.
Tvůj cíl
Prvním prvkem, který musíte definovat, je cíl s vašimi koncepty umělé inteligence a strojového učení.
- Proč je implementujete do svého podnikání?
- Vyřeší skutečný problém, kterému vaši zákazníci čelí?
- Dělají nějaký front-end nebo backend proces?
- Využijete AI k představení nových funkcí nebo k optimalizaci svého stávajícího webu, aplikace nebo modulu?
- Co dělá váš konkurent ve vašem segmentu?
- Máte dostatek případů použití, které vyžadují zásah AI?
Odpovědi na tyto informace spojí vaše myšlenky - které mohou být v současné době všude - do jednoho místa a poskytnou vám větší jasnost.
Sběr dat / licencování AI
Modely AI vyžadují pro fungování pouze jeden prvek - data. Musíte zjistit, odkud lze generovat obrovské objemy dat pozemské pravdy. Pokud vaše firma generuje velké objemy dat, které je třeba zpracovat, aby bylo možné získat zásadní poznatky o podnikání, operacích, průzkumu konkurence, analýze volatility trhu, studii chování zákazníků a dalších, potřebujete nástroj pro anotaci dat. Měli byste však také zvážit objem dat, která generujete. Jak již bylo zmíněno dříve, model AI je pouze tak účinný jako kvalita a množství dat, ze kterých je dodáván. Vaše rozhodnutí by tedy měla vždy záviset na tomto faktoru.
Pokud nemáte správná data pro trénování svých modelů ML, mohou se vám prodejci docela hodit a pomoci vám s licencí na data pro správnou sadu dat potřebných k trénování modelů ML. V některých případech bude část hodnoty, kterou prodejce přináší, zahrnovat jak technickou zdatnost, tak také přístup ke zdrojům, které podpoří úspěch projektu.
Rozpočet
Další zásadní podmínka, která pravděpodobně ovlivňuje každý jednotlivý faktor, o kterém v současné době diskutujeme. Řešení otázky, zda byste měli vytvořit nebo koupit anotaci dat, je snadné, když pochopíte, zda máte dostatek rozpočtu na útratu.
Složitost dodržování předpisů
 Prodejci mohou být nesmírně užiteční, pokud jde o ochranu osobních údajů a správné zacházení s citlivými údaji. Jeden z těchto typů případů použití zahrnuje nemocnici nebo podnik související se zdravotní péčí, který chce využít sílu strojového učení, aniž by to ohrozilo jeho soulad s HIPAA a dalšími pravidly ochrany osobních údajů. Zákony, jako je evropské nařízení GDPR, zpřísňují kontrolu nad datovými soubory i mimo oblast medicíny a vyžadují větší ostražitost ze strany firemních zúčastněných stran.
Prodejci mohou být nesmírně užiteční, pokud jde o ochranu osobních údajů a správné zacházení s citlivými údaji. Jeden z těchto typů případů použití zahrnuje nemocnici nebo podnik související se zdravotní péčí, který chce využít sílu strojového učení, aniž by to ohrozilo jeho soulad s HIPAA a dalšími pravidly ochrany osobních údajů. Zákony, jako je evropské nařízení GDPR, zpřísňují kontrolu nad datovými soubory i mimo oblast medicíny a vyžadují větší ostražitost ze strany firemních zúčastněných stran.
Pracovní síla
Anotace dat vyžaduje práci kvalifikovaných pracovníků bez ohledu na velikost, rozsah a doménu vaší firmy. I když generujete holé minimum dat každý den, potřebujete odborníky na data, aby pracovali na vašich datech pro označování. Takže teď si musíte uvědomit, zda máte požadovanou pracovní sílu. Pokud ano, jsou zruční v požadovaných nástrojích a technikách nebo potřebují dovednosti? Pokud potřebují zvýšení kvalifikace, máte rozpočet na jejich školení?
Nejlepší programy pro anotace a označování dat navíc využívají řadu odborníků na dané oblasti nebo oblasti a segmentují je podle demografických údajů, jako je věk, pohlaví a oblast odbornosti - nebo často podle lokalizovaných jazyků, se kterými budou pracovat. To je opět místo, kde v Shaipu hovoříme o tom, jak dostat správné lidi na správná místa, a tím řídit správné procesy typu „člověk ve smyčce“, které povedou vaše programové úsilí k úspěchu.
Provoz malých a velkých projektů a limity nákladů
V mnoha případech může být podpora dodavatele spíše možností pro menší projekt nebo pro menší fáze projektu. Když jsou náklady pod kontrolou, může společnost těžit z outsourcingu, aby byla anotace dat nebo projekty označování dat efektivnější.
Společnosti se mohou také podívat na důležité prahové hodnoty - kde mnoho prodejců váže náklady na množství spotřebovaných dat nebo jiná měřítka zdrojů. Řekněme například, že se společnost zaregistrovala u dodavatele, který provádí zdlouhavé zadávání dat potřebné k nastavení testovacích sad.
Ve smlouvě může existovat skrytá prahová hodnota, kdy například obchodní partner musí vyjmout další blok datového úložiště AWS nebo nějakou jinou komponentu služby od Amazon Web Services nebo jiného dodavatele třetí strany. Přenášejí to na zákazníka v podobě vyšších nákladů a cenovka je mimo dosah zákazníka.
V těchto případech měření služeb, které získáte od prodejců, pomáhá udržet cenově dostupný projekt. Zavedení správného rozsahu zajistí, že náklady na projekt nepřesáhnou to, co je pro danou firmu přiměřené nebo proveditelné.
Alternativy open source a freeware
 Některé alternativy k plné podpoře prodejců zahrnují použití softwaru s otevřeným zdrojovým kódem nebo dokonce freeware k provádění anotací dat nebo projektů označování. Zde je jakýsi druh cesty, kde společnosti nevytvářejí vše od nuly, ale také se vyhýbají přílišnému spoléhání se na komerční prodejce.
Některé alternativy k plné podpoře prodejců zahrnují použití softwaru s otevřeným zdrojovým kódem nebo dokonce freeware k provádění anotací dat nebo projektů označování. Zde je jakýsi druh cesty, kde společnosti nevytvářejí vše od nuly, ale také se vyhýbají přílišnému spoléhání se na komerční prodejce.
Mentalita otevřeného zdroje typu „udělej si sám“ je sama o sobě jakýmsi kompromisem - inženýři a interní lidé mohou využívat komunitu otevřeného zdroje, kde decentralizované uživatelské základny nabízejí své vlastní druhy základní podpory. Nebude to jako to, co získáte od prodejce - bez interního průzkumu nedostanete 24/7 snadnou pomoc nebo odpovědi na otázky - ale cena je nižší.
Takže velká otázka - Kdy byste si měli koupit nástroj pro anotaci dat:
Stejně jako u mnoha druhů high-tech projektů vyžaduje i tento typ analýzy - kdy je třeba je postavit a kdy koupit - důkladné promyšlení a zvážení toho, jak jsou tyto projekty získávány a řízeny. Výzvy, kterým většina společností čelí v souvislosti s projekty AI / ML, když zvažují možnost „sestavit“, nejsou jen části budování a rozvoje projektu. Často existuje obrovská křivka učení, která se dokonce dostane do bodu, kdy může dojít ke skutečnému vývoji AI / ML. S novými týmy a iniciativami AI / ML počet „neznámých neznámých“ daleko převyšuje počet „známých neznámých“.
| Vytvořit | Koupit |
|---|---|
Klady:
| Klady:
|
Nevýhody:
| Nevýhody:
|
Aby byly věci ještě jednodušší, zvažte následující aspekty:
- když pracujete na velkém objemu dat
- když pracujete na různých variantách dat
- kdy by se funkce spojené s vašimi modely nebo řešeními mohly v budoucnu změnit nebo vyvinout
- když máte nejasný nebo obecný případ použití
- když potřebujete jasnou představu o nákladech spojených s nasazením nástroje pro anotaci dat
- a když nemáte správné pracovní síly nebo kvalifikované odborníky, kteří by pracovali na těchto nástrojích, a hledáte minimální křivku učení
Pokud byly vaše reakce opačné než tyto scénáře, měli byste se zaměřit na vytvoření svého nástroje.
Jak vybrat správný nástroj pro anotaci dat pro váš projekt
Pokud to čtete, tyto nápady zní vzrušující a rozhodně se snadněji řeknou, než udělají. Jak je tedy možné využít nepřeberné množství již existujících nástrojů pro anotaci dat? Dalším zapojeným krokem je tedy zvážení faktorů spojených s výběrem správného nástroje pro anotaci dat.
Na rozdíl od několika let zpět se trh v současné době v praxi vyvinul s množstvím nástrojů pro anotaci dat. Firmy mají více možností, jak si vybrat jednu na základě svých odlišných potřeb. Ale každý nástroj má své vlastní výhody a nevýhody. Aby bylo možné učinit moudré rozhodnutí, je třeba vyjmout objektivní cestu kromě subjektivních požadavků.
Pojďme se podívat na některé z klíčových faktorů, které byste měli v procesu zvážit.
Definování vašeho případu použití
Chcete-li vybrat správný nástroj pro anotaci dat, musíte definovat svůj případ použití. Měli byste si uvědomit, zda váš požadavek zahrnuje text, obrázek, video, zvuk nebo kombinaci všech datových typů. Existují samostatné nástroje, které si můžete koupit, a existují holistické nástroje, které vám umožňují provádět různé akce se soubory dat.
Dnešní nástroje jsou intuitivní a nabízejí vám možnosti, pokud jde o úložná zařízení (síťová, místní nebo cloudová), techniky anotací (zvukové, obrazové, 3D a další) a řadu dalších aspektů. Můžete si vybrat nástroj na základě vašich konkrétních požadavků.
Stanovení standardů kontroly kvality
 Toto je zásadní faktor, který je třeba vzít v úvahu, protože účel a efektivita vašich modelů AI závisí na standardech kvality, které stanovíte. Stejně jako audit musíte provádět kontroly kvality dat, která vkládáte, a získaných výsledků, abyste pochopili, zda jsou vaše modely trénovány správným způsobem a pro správné účely. Otázkou však je, jak hodláte zavést standardy kvality?
Toto je zásadní faktor, který je třeba vzít v úvahu, protože účel a efektivita vašich modelů AI závisí na standardech kvality, které stanovíte. Stejně jako audit musíte provádět kontroly kvality dat, která vkládáte, a získaných výsledků, abyste pochopili, zda jsou vaše modely trénovány správným způsobem a pro správné účely. Otázkou však je, jak hodláte zavést standardy kvality?
Stejně jako u mnoha různých druhů úloh může mnoho lidí provádět anotace a označování dat, ale dělají to s různým stupněm úspěchu. Když požádáte o službu, neověříte automaticky úroveň kontroly kvality. Proto se výsledky liší.
Chcete tedy nasadit model konsensu, kde anotátoři nabízejí zpětnou vazbu o kvalitě a jsou okamžitě přijata nápravná opatření? Nebo dáváte přednost vzorovým recenzím, zlatým standardům nebo průniku před unijními modely?
Nejlepší nákupní plán zajistí, že kontrola kvality bude zavedena od samého začátku stanovením standardů před uzavřením jakékoli konečné smlouvy. Při stanovení tohoto byste neměli přehlédnout také chybové okraje. Manuálnímu zásahu se nelze zcela vyhnout, protože systémy jsou povinny produkovat chyby rychlostí až 3%. To dělá práci předem, ale stojí to za to.
Kdo bude anotovat vaše údaje?
Další hlavní faktor závisí na tom, kdo anotuje vaše data. Máte v úmyslu mít interní tým, nebo byste jej chtěli získat externě? Pokud zadáváte outsourcing, musíte vzít v úvahu zákonnost a opatření k dodržování předpisů z důvodu obav o ochranu soukromí a důvěrnosti dat. A pokud máte interní tým, jak efektivní jsou při učení nového nástroje? Jaký je váš čas uvedení na trh s vaším produktem nebo službou? Máte správné metriky kvality a týmy pro schvalování výsledků?
Prodejce vs. Debata partnera
 Datová anotace je proces spolupráce. Zahrnuje závislosti a složitosti, jako je interoperabilita. To znamená, že určité týmy vždy spolupracují v tandemu a jeden z týmů může být vaším prodejcem. Proto je vámi vybraný prodejce nebo partner stejně důležitý jako nástroj, který používáte pro označování dat.
Datová anotace je proces spolupráce. Zahrnuje závislosti a složitosti, jako je interoperabilita. To znamená, že určité týmy vždy spolupracují v tandemu a jeden z týmů může být vaším prodejcem. Proto je vámi vybraný prodejce nebo partner stejně důležitý jako nástroj, který používáte pro označování dat.
S tímto faktorem je třeba vzít v úvahu aspekty, jako je schopnost uchovat vaše data a záměry v tajnosti, záměr přijmout a pracovat na zpětné vazbě, být proaktivní, pokud jde o požadavky na data, flexibilita v operacích a další, než si podáte ruku s prodejcem nebo partnerem . Zahrnuli jsme flexibilitu, protože požadavky na anotace dat nejsou vždy lineární nebo statické. Mohou se v budoucnu změnit, jak budete své podnikání dále rozšiřovat. Pokud aktuálně pracujete pouze s textovými daty, možná budete chtít anotovat zvuková nebo obrazová data, jak budete škálovat, a vaše podpora by měla být připravena rozšířit jejich obzory s vámi.
Zapojení dodavatele
Jedním ze způsobů, jak posoudit zapojení dodavatele, je podpora, kterou obdržíte.
Jakýkoli plán nákupu musí tuto komponentu nějak zohlednit. Jak bude vypadat podpora na zemi? Kdo budou na obou stranách rovnice zúčastněné strany a směřující lidé?
Existují také konkrétní úkoly, které musí vysvětlit, co je (nebo bude) zapojení dodavatele. Zejména u projektu anotace dat nebo označení dat bude dodavatel aktivně poskytovat nezpracovaná data, nebo ne? Kdo bude působit jako odborník na předmět a kdo je zaměstná jako zaměstnance nebo nezávislého dodavatele?
Ukázkové studie
Zde je několik konkrétních příkladů případových studií, které se zabývají tím, jak anotace dat a označování dat skutečně fungují v praxi. Ve společnosti Shaip dbáme na to, abychom poskytli nejvyšší úroveň kvality a vynikající výsledky v anotaci dat a označování dat.
Hodně z výše uvedené diskuse o standardních úspěších pro anotaci dat a označování dat odhaluje, jak přistupujeme ke každému projektu a co nabízíme společnostem a zúčastněným stranám, se kterými pracujeme.
Materiály případové studie, které ukážou, jak to funguje:

V projektu licencování klinických dat tým Shaip zpracoval více než 6,000 XNUMX hodin zvuku, odstranil všechny chráněné informace o zdraví (PHI) a ponechal obsah kompatibilní s HIPAA pro modely rozpoznávání řeči ve zdravotnictví, na kterých bude pracovat.
V tomto typu případů jsou důležitá kritéria a klasifikace úspěchů. Nezpracovaná data jsou ve formě zvuku a je potřeba deidentifikovat strany. Například při použití analýzy NER je dvojím cílem de-identifikovat a anotovat obsah.
Další případová studie zahrnuje hloubku konverzační tréninková data AI projekt, který jsme dokončili s 3,000 14 lingvisty pracujícími po dobu 27 týdnů. To vedlo k produkci školicích dat ve XNUMX jazycích s cílem vyvinout vícejazyčné digitální asistenty schopné zvládnout lidské interakce v širokém výběru rodných jazyků.
V této konkrétní případové studii byla zřejmá potřeba dostat správnou osobu na správné křeslo. Velký počet odborníků na předmět a provozovatelů vstupů obsahu znamenal, že je potřeba organizační a procedurální zefektivnění, aby byl projekt proveden na konkrétní časové ose. Náš tým dokázal překonat průmyslový standard s velkým náskokem díky optimalizaci sběru dat a následných procesů.
Jiné typy případových studií zahrnují věci, jako je trénink robotů a anotace textu pro strojové učení. Opět platí, že v textovém formátu je stále důležité zacházet s identifikovanými stranami podle zákonů o ochraně osobních údajů a třídit nezpracovaná data, abyste dosáhli cílených výsledků.
Jinými slovy, při práci s více datovými typy a formáty Shaip prokázal stejný zásadní úspěch tím, že použil stejné metody a principy na obchodní scénáře nezpracovaných dat i datových licencí.