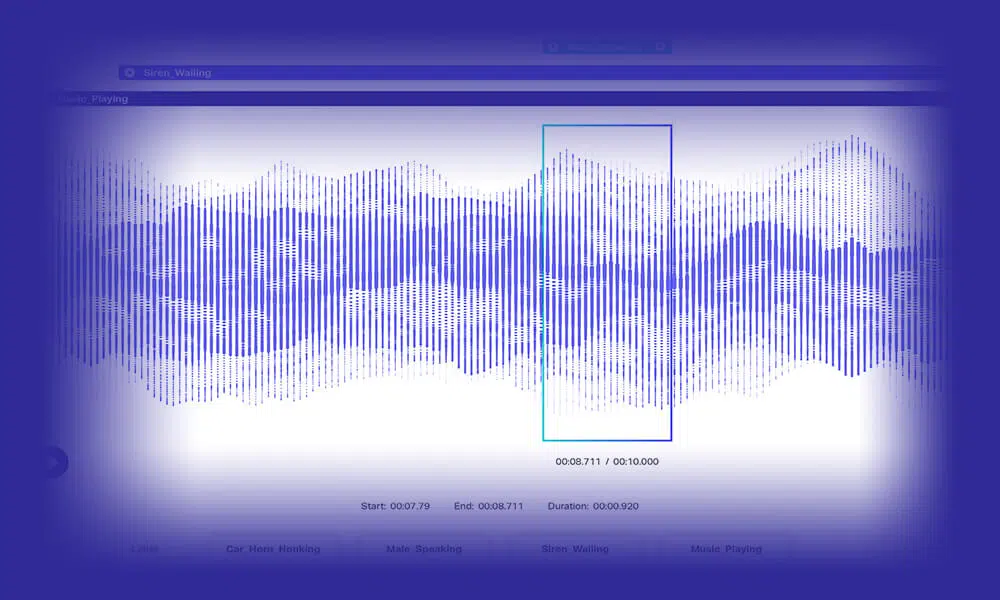


Přepis zvuku
Vyvíjejte inteligentní modely NLP vkládáním nákladu přesně přepsaných dat řeči/ zvuku. Ve společnosti Shaip vám dáváme na výběr z širší sady možností, včetně standardního zvukového, doslovného a vícejazyčného přepisu. Navíc můžete trénovat modely s dalšími identifikátory reproduktorů a údaji o časovém razítku.
Označování řeči
Označování řeči nebo zvuku je standardní anotační technika, která se týká oddělení zvuků a označování konkrétními metadaty. Podstata této techniky zahrnuje ontologickou identifikaci zvuků ze zvukového záznamu a jejich přesné anotování, aby byly tréninkové datové sady inkluzivnější

Klasifikace zvuku
Používají ho společnosti zabývající se anotací řeči k vycvičení AI k dokonalosti, pokud jde o analýzu zvukových nahrávek podle obsahu. Díky klasifikaci zvuku mohou stroje identifikovat hlasy a zvuky, přičemž jsou schopny je rozlišit, jako součást proaktivnějšího tréninkového režimu.

Vícejazyčné zvukové datové služby
Shromažďování vícejazyčných zvukových dat je užitečné pouze tehdy, pokud je mohou anotátoři odpovídajícím způsobem označit a segmentovat. Zde se hodí vícejazyčné zvukové datové služby, které se týkají anotace řeči na základě rozmanitosti jazyka, kterou mají příslušná umělá inteligence dokonale identifikovat a analyzovat

Přirozený jazyk
Promluva
NLU se zabývá anotováním lidské řeči za účelem klasifikace těch nejmenších detailů, jako je sémantika, dialekty, kontext, stres a další. Tato forma anotovaných dat má smysl při lepším školení virtuálních asistentů a chatbotů.
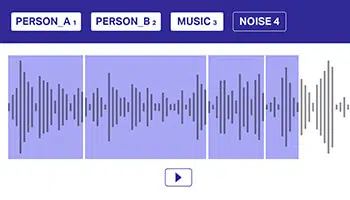
Multi-Label
Anotace
Přidávání poznámek ke zvukovým datům pomocí několika štítků je důležité, aby modely mohly rozlišovat překrývající se zvukové zdroje. V tomto přístupu může audio datový soubor patřit do jedné nebo mnoha tříd, které je třeba explicitně předat modelu pro lepší rozhodování.

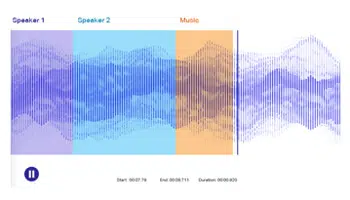
Diarizace reproduktorů
Zahrnuje rozdělení vstupního zvukového souboru do homogenních segmentů spojených s jednotlivými reproduktory. Diarizace znamená identifikaci hranic reproduktorů a seskupování zvukových souborů do segmentů pro určení počtu odlišných reproduktorů. Tento proces pomáhá automatizovat analýzu konverzace a přepis dialogů call centra, lékařských a právních rozhovorů a schůzek.

Fonetický přepis
Na rozdíl od běžného přepisu, který převádí zvuk na sekvenci slov, fonetický přepis zaznamenává, jak se slova vyslovují, a vizuálně reprezentuje zvuky pomocí fonetických symbolů. Fonetický přepis usnadňuje zaznamenání rozdílu ve výslovnosti stejného jazyka v několika dialektech.

Lidé
Specializované a vyškolené týmy:
- Více než 30,000 XNUMX spolupracovníků pro vytváření, označování a kontrolu dat
- Tým pověřeného řízení projektů
- Zkušený tým vývoje produktů
- Tým získávání a přihlašování talentů

Proces
Nejvyšší účinnost procesu je zajištěna pomocí:
- Robustní 6stupňový proces sigma-gate
- Specializovaný tým 6 černých pásů Sigma - klíčoví vlastníci procesů a dodržování kvality
- Neustálé zlepšování a zpětná vazba

Plošina
Patentovaná platforma nabízí výhody:
- Webová platforma typu end-to-end
- Bezvadná kvalita
- Rychlejší TAT
- Bezproblémové doručení
Lidé
Specializované a vyškolené týmy:
- Více než 30,000 XNUMX spolupracovníků pro vytváření, označování a kontrolu dat
- Tým pověřeného řízení projektů
- Zkušený tým vývoje produktů
- Tým získávání a přihlašování talentů
Proces
Nejvyšší účinnost procesu je zajištěna pomocí:
- Robustní 6stupňový proces sigma-gate
- Specializovaný tým 6 černých pásů Sigma - klíčoví vlastníci procesů a dodržování kvality
- Neustálé zlepšování a zpětná vazba
Plošina
Patentovaná platforma nabízí výhody:
- Webová platforma typu end-to-end
- Bezvadná kvalita
- Rychlejší TAT
- Bezproblémové doručení

Textová anotace
Služby
Specializujeme se na přípravu školení textových dat anotováním vyčerpávajících datových sad, pomocí anotace entit, klasifikace textu, anotace sentimentu a dalších relevantních nástrojů.

Anotace obrázku
Služby
Jsme pyšní na označování, segmentované datové sady obrázků pro trénování modelů počítačového vidění. Některé z relevantních technik zahrnují rozpoznávání hranic a klasifikaci obrazu.

Video anotace
Služby
Shaip nabízí špičkové služby označování videa pro školení modelů Computer Vision. Cílem je učinit datové sady použitelné pomocí nástrojů, jako je rozpoznávání vzorů, detekce objektů a další.


