
Umělá inteligence přináší revoluci v hudebním průmyslu a nabízí nástroje pro automatizovanou kompozici, mastering a performance. Algoritmy umělé inteligence generují nové kompozice, předpovídají hity a personalizují zážitek posluchače, čímž transformují hudební produkci, distribuci a spotřebu. Tato vznikající technologie představuje vzrušující příležitosti i náročná etická dilemata.
Modely strojového učení (ML) vyžadují trénovací data, aby fungovaly efektivně, protože skladatel potřebuje hudební noty, aby napsal symfonii. V hudebním světě, kde se melodie, rytmus a emoce prolínají, nelze důležitost kvalitních tréninkových dat přeceňovat. Je to páteř vývoje robustních a přesných hudebních ML modelů pro prediktivní analýzu, žánrovou klasifikaci nebo automatický přepis.
Data, míza ML modelů
Strojové učení je ze své podstaty založeno na datech. Tyto výpočetní modely se učí vzory z dat a umožňují jim předpovídat nebo rozhodovat. U hudebních modelů ML jsou tréninková data často dodávána v digitalizovaných hudebních stopách, textech, metadatech nebo kombinaci těchto prvků. Kvalita, kvantita a rozmanitost těchto dat významně ovlivňuje efektivitu modelu.

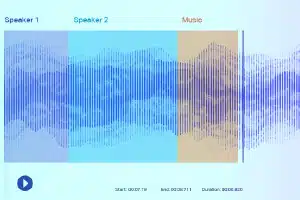
Zvukové značení
Při označování zvukem dostanou anotátoři dat nahrávku a potřebují oddělit všechny potřebné zvuky a označit je. Mohou to být například určitá klíčová slova nebo zvuk konkrétního hudebního nástroje.

Klasifikace hudby
Anotátoři dat mohou v tomto druhu zvukové anotace označovat žánry nebo nástroje. Klasifikace hudby je velmi užitečná pro organizaci hudebních knihoven a zlepšení doporučení uživatelů.

Fonetická segmentace úrovně
Označení a klasifikace fonetických úseků na křivkách a spektrogramech nahrávek jedinců zpívajících acapella.
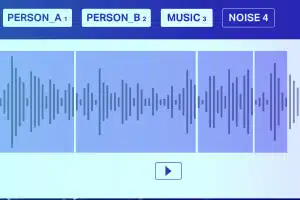
Klasifikace zvuku
Kromě ticha/bílého šumu se zvukový soubor obvykle skládá z následujících typů zvuku Řeč, Blábol, Hudba a Hluk. Přesné poznámky k hudebním notám pro vyšší přesnost.
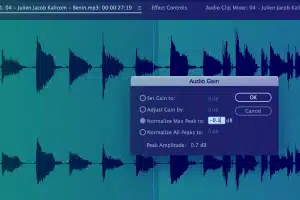
Zachycování metadat informací
Zachyťte důležité informace, jako je čas začátku, čas ukončení, ID segmentu, úroveň hlasitosti, primární typ zvuku, kód jazyka, ID reproduktoru a další konvence přepisu atd.


