
Velké jazykové modely nedávno získaly masivní význam poté, co se jejich vysoce kompetentní případ použití ChatGPT stal přes noc úspěchem. Po úspěchu ChatGPT a dalších ChatBotů se mnoho lidí a organizací začalo zajímat o zkoumání technologie, která takový software pohání.
Velké jazykové modely jsou páteří tohoto softwaru, který umožňuje fungování různých aplikací pro zpracování přirozeného jazyka, jako je strojový překlad, rozpoznávání řeči, odpovídání na otázky a sumarizace textu. Pojďme se dozvědět více o LLM a o tom, jak jej můžete optimalizovat pro dosažení nejlepších výsledků.
Co jsou velké jazykové modely nebo ChatGPT?
Velké jazykové modely jsou model strojového učení, který využívá umělé neuronové sítě a velká sila dat k napájení aplikací NLP. Tréninkem na velkém množství dat získává LLM schopnost zachytit různé složitosti přirozeného jazyka, které dále využil pro:
- Generování nového textu
- Sumarizace článků a pasáží
- Extrakce dat
- Přepisování nebo parafrázování textu
- Klasifikace dat
Některé populární příklady LLM jsou BERT, Chat GPT-3 a XLNet. Tyto modely jsou trénovány na stovkách milionů textů a mohou poskytnout hodnotná řešení pro všechny typy různých uživatelských dotazů.
Populární případy použití velkých jazykových modelů
Zde jsou některé z hlavních a nejrozšířenějších případů použití LLM:
Generování textu
Velké jazykové modely využívají umělou inteligenci a znalosti výpočetní lingvistiky k automatickému generování textů v přirozeném jazyce a plnění různých komunikativních uživatelských požadavků, jako je psaní článků, písní nebo dokonce chatování s uživateli.
Strojový překlad
LLM lze také použít k překladu textu mezi libovolnými dvěma jazyky. Modely využívají algoritmy hlubokého učení, jako jsou rekurentní neuronové sítě, aby se naučily jazykovou strukturu zdrojového a cílového jazyka. V souladu s tím se používají pro překlad zdrojového textu do cílového jazyka.
Tvorba obsahu
LLM nyní umožnily strojům vytvářet koherentní a logický obsah, který lze použít ke generování blogových příspěvků, článků a dalších forem obsahu. Modely využívají své rozsáhlé znalosti hlubokého učení k pochopení a strukturování obsahu v jedinečném a pro uživatele čitelném formátu.
Analýza sentimentu
Je to vzrušující případ použití velkých jazykových modelů, kde je model trénován k identifikaci a klasifikaci emočních stavů a pocitů v označeném textu. Software dokáže detekovat emoce, jako je pozitivita, negativita, neutralita a další složité pocity, které mohou pomoci získat přehled o názorech a recenzích zákazníků na různé produkty a služby.
Porozumění, shrnutí a klasifikace textu
LLM poskytují praktický rámec pro software AI pro pochopení textu a jeho kontextu. Trénováním modelu, aby porozuměl a analyzoval velké hromady dat, umožňuje LLM modelům umělé inteligence porozumět, shrnout a dokonce klasifikovat text do různých forem a vzorů.
Odpověď na otázku
Velké jazykové modely umožňují systémům kontroly kvality přesně detekovat a reagovat na dotaz uživatele v přirozeném jazyce. Jednou z nejoblíbenějších aplikací tohoto případu použití jsou ChatGPT a BERT, které analyzují kontext dotazu a prohledávají velký korpus textů, aby nalezly relevantní odpovědi na dotazy uživatelů.
[Přečtěte si také: Budoucnost jazykového zpracování: Velké jazykové modely a příklady ]

3 základní podmínky, aby byly LLM úspěšné
Pro zvýšení efektivity a úspěch vašich velkých jazykových modelů musí být přesně splněny následující tři podmínky:
Přítomnost obrovského množství dat pro modelový trénink
LLM potřebuje velké množství dat pro trénování modelů, které poskytují efektivní a optimální výsledky. Existují specifické metody, jako je přenos učení a předškolení s vlastním dohledem, které LLM využívají ke zlepšení svého výkonu a přesnosti.
Budování vrstev neuronů pro usnadnění složitých vzorů modelů
Velký jazykový model musí obsahovat různé vrstvy neuronů speciálně vyškolených k pochopení složitých vzorců v datech. Neurony v hlubších vrstvách dokážou lépe chápat složité vzory než mělčí vrstvy. Model se může naučit asociaci mezi slovy, témata, která se objevují společně, a vztah mezi částmi řeči.
Optimalizace LLM pro úkoly specifické pro uživatele
LLM mohou být vyladěny pro konkrétní úkoly změnou počtu vrstev, neuronů a aktivačních funkcí. Například model, který předpovídá následující slovo ve větě, obvykle používá méně vrstev a neuronů než model navržený pro generování nových vět od začátku.
Oblíbené příklady velkých jazykových modelů
Zde je několik prominentních příkladů LLM široce používaných v různých průmyslových odvětvích:
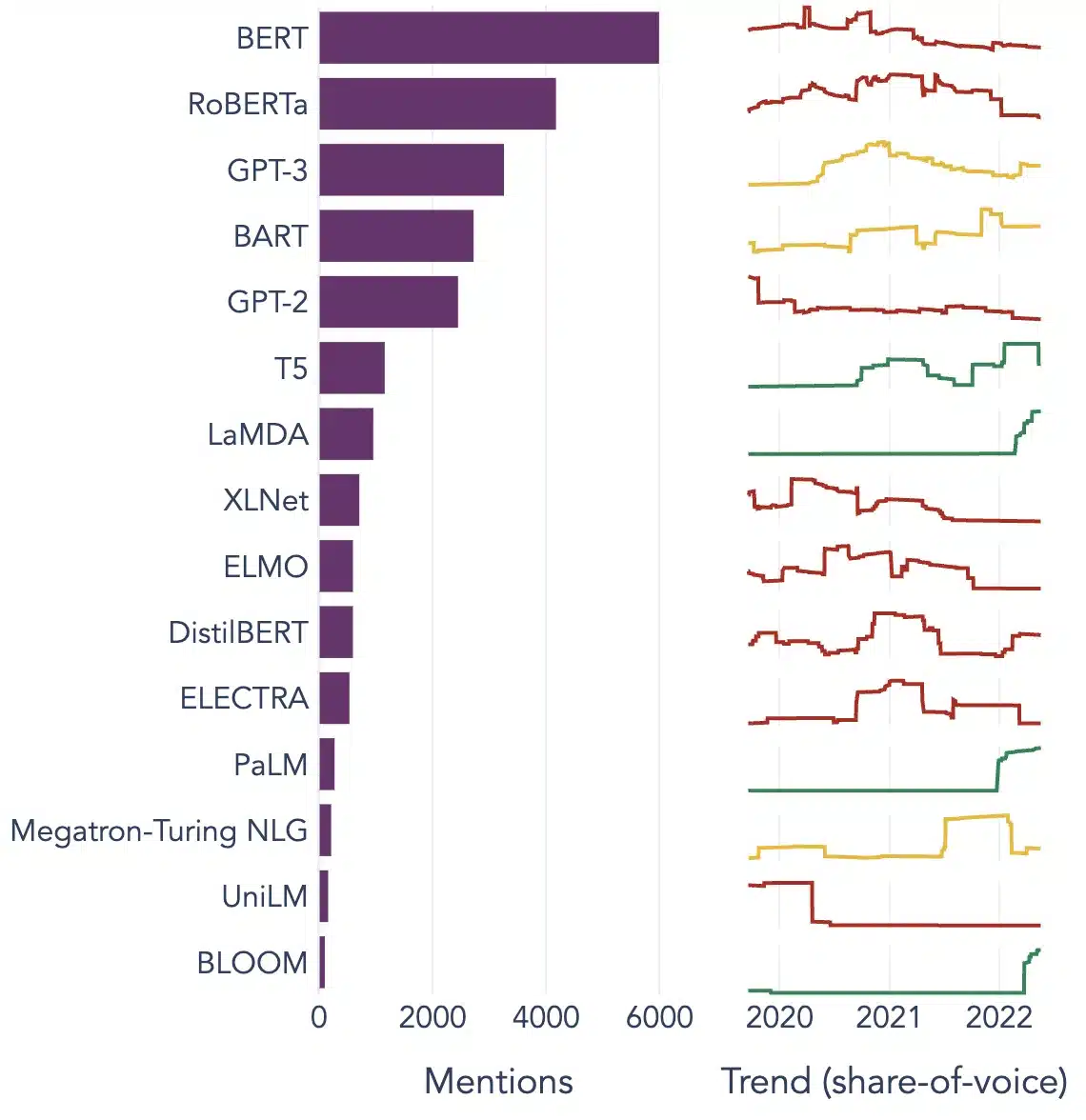
Zdroj obrázku: Směrem k datové vědě
Proč investovat do čističky vzduchu?
LLM vidí potenciál převratu v NLP tím, že poskytují robustní a přesné schopnosti a řešení pro porozumění jazyku, která poskytují bezproblémovou uživatelskou zkušenost. Aby však LLM byly efektivnější, musí vývojáři využít vysoce kvalitní data řeči, aby generovali přesnější výsledky a produkovali vysoce efektivní modely umělé inteligence.
Shaip je jedním z předních technologických řešení AI, které nabízí širokou škálu dat řeči ve více než 50 jazycích a různých formátech. Zjistěte více o LLM a získejte pokyny pro své projekty Shaip odborníci dnes.


